다익스트라(dijkstra) 알고리즘
Posted
By ROOT
9 min read
🤔 다익스트라 알고리즘이란?
- 최단 경로 탐색 알고리즘이다.
- 하나의 정점에서 다른 모든 정점으로 가는 최단 경로를 알 수 있다.
- 간선의 가중치는 음수를 포함할 수 없다.
- DP를 그래프로 확장시킨 것과 같다.
😮 다익스트라가 DP 유형인 이유
- DP - Dynamic Programming
- 위 내용에 따르면 DP는 다음 2가지 조건으르 만족해야 한다.
- Overlapping Subproblems(겹치는 부분 문제)
- Optimal Substructure(최적 부분 구조)
- 위 조건들을 만족하는지 간단하게 알아보겠다.
- 위 내용에 따르면 DP는 다음 2가지 조건으르 만족해야 한다.
예시 그래프
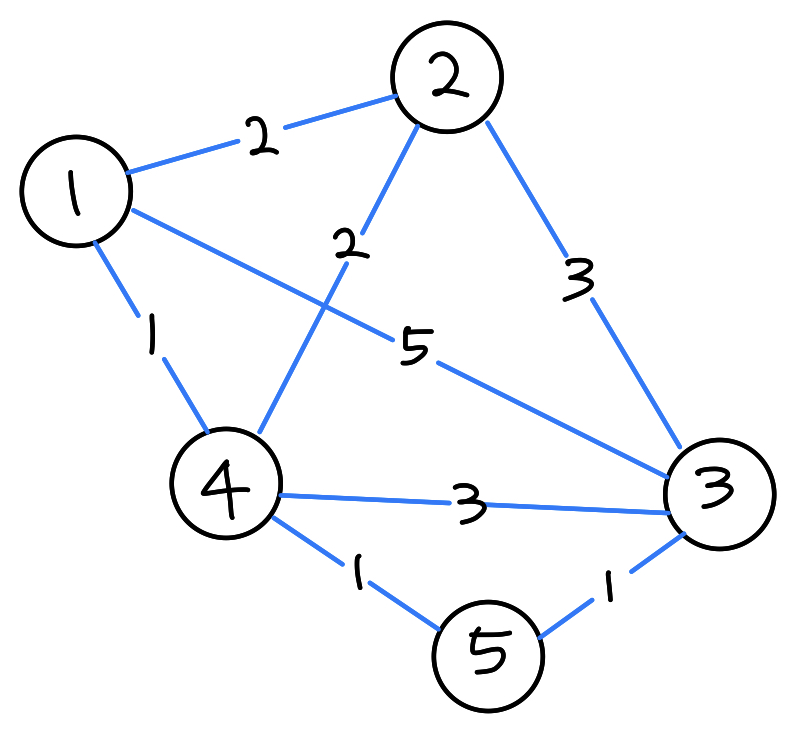
[겹치는 부분 문제]
- 정점 1에서 각 정점까지의 최소 거리를 구한다고 가정했을 때 다음과 같은 경로가 나올 것이다.
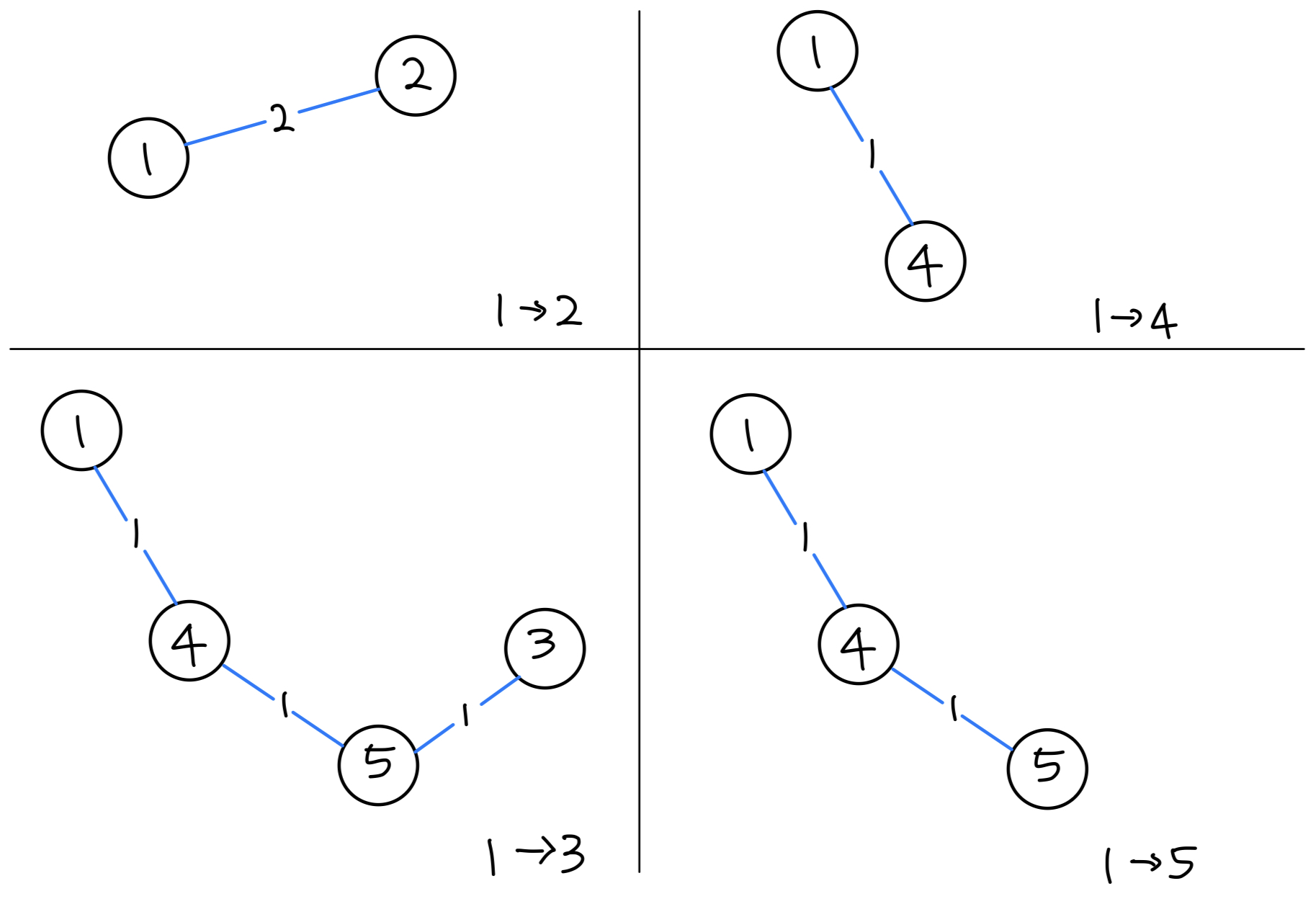
1 -> 3경로를 보면1 -> 5의 경로를 똑같이 이용했다는 것을 볼 수 있다.- 따라서 겹치는 부분 문제 조건은 만족한다.
[최적 부분 구조]
- 정점 1에서 정점 3 까지의 최소 거리는 정점 1에서 정점 5까지의 최소 거리와 정점 5부터 정점 3 까지의 최소 거리의 합이다.
- 따라서 최적 부분 구조 조건은 만족하다.
이렇게 2가지 조건을 만족하기 때문에 DP 유형으로 분류할 수 있다!
🧐 다익스트라 로직
개인적으로 DP의 유형이지만 그래프의 형태를 처리해야 하다 보니 코드 양이 많고 빠른 학습이 어려웠다. 차근차근 살펴보자.
사용했던 그래프로 정점 1에서 출발하는 것으로 알아보겠다.
- 각 정점까지의 거리를 저장하는 거리 배열을 생성하고 무한으로 초기화한다.
- 현재 정점에서 갈 수 있는 경로를 탐색한다.
처음은 시작 정점에서 탐색한다.
- 해당 경로가 기존 거리보다 짧다면 해당 거리를 업데이트한다.
- 각 경로 값에 대해 변경이 일어났으면 우선순위 큐 안에 정점 이름과 거리를 넣는다.
또한 방문했던 정점은 다시 방문하지 않는다.
- 모든 정점을 탐색할 때까지 2-5 를 반복한다.
[탐색 시작 전 각 정점까지의 거리 설정]
- 각 인덱스는 정점을 의미한다.
- 0번 인덱스는 없으므로 편의를 위해 N+1 크기의 배열을 설정한다.
| 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| - | 무한 | 무한 | 무한 | 무한 | 무한 |
[탐색 시작]
- 시작 정점 1부터 시작한다.
- 자기 자신으로 가는 거리는 0이다.
- 1에서 다른 정점으로의 경로가 있는지 확인하고 해당 경로의 거리가 더 가깝다면 거리 배열의 값을 업데이트한다.
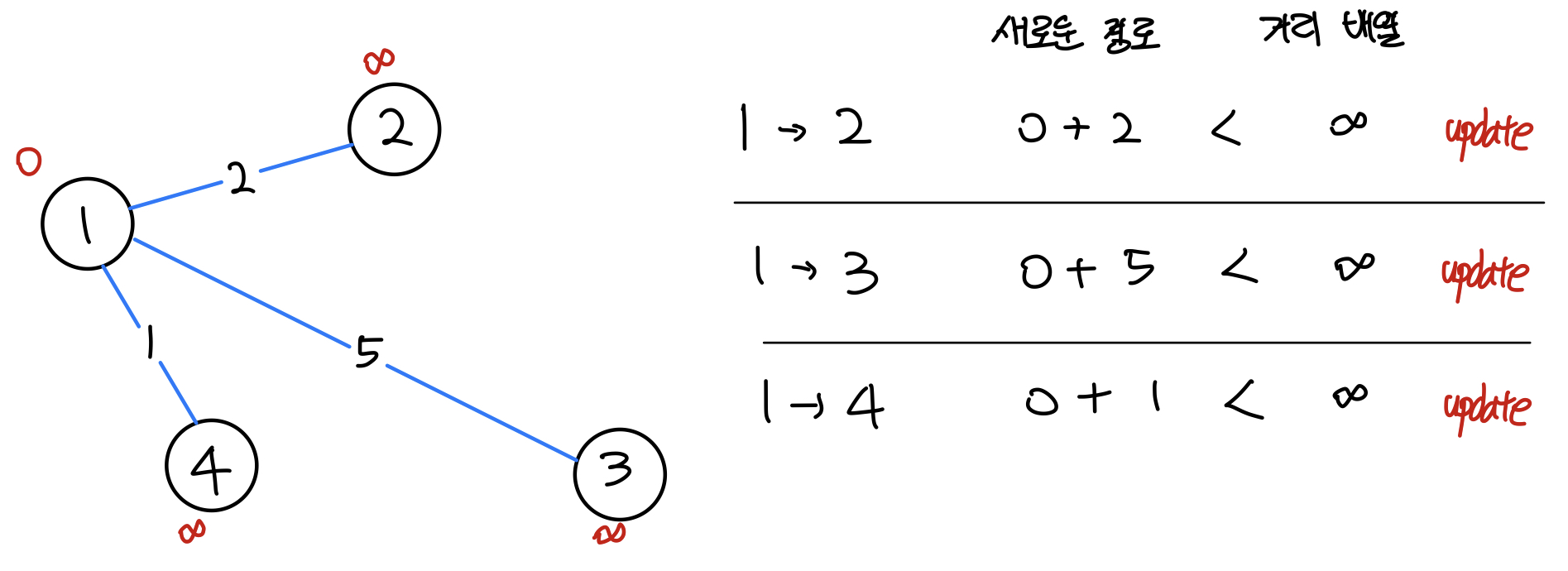
| 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| - | 0 | 2 | 5 | 1 | 무한 |
- 현재 우선순위 큐
- (정점, 가중치)
- (2, 2)
- (3, 5)
- (4, 1)
[2번째 탐색]
- 우선순위로부터 가중치가 가장 낮은 정점을 선택한다.
- 가중치가 가장 낮은 4번 노드를 선택한다.
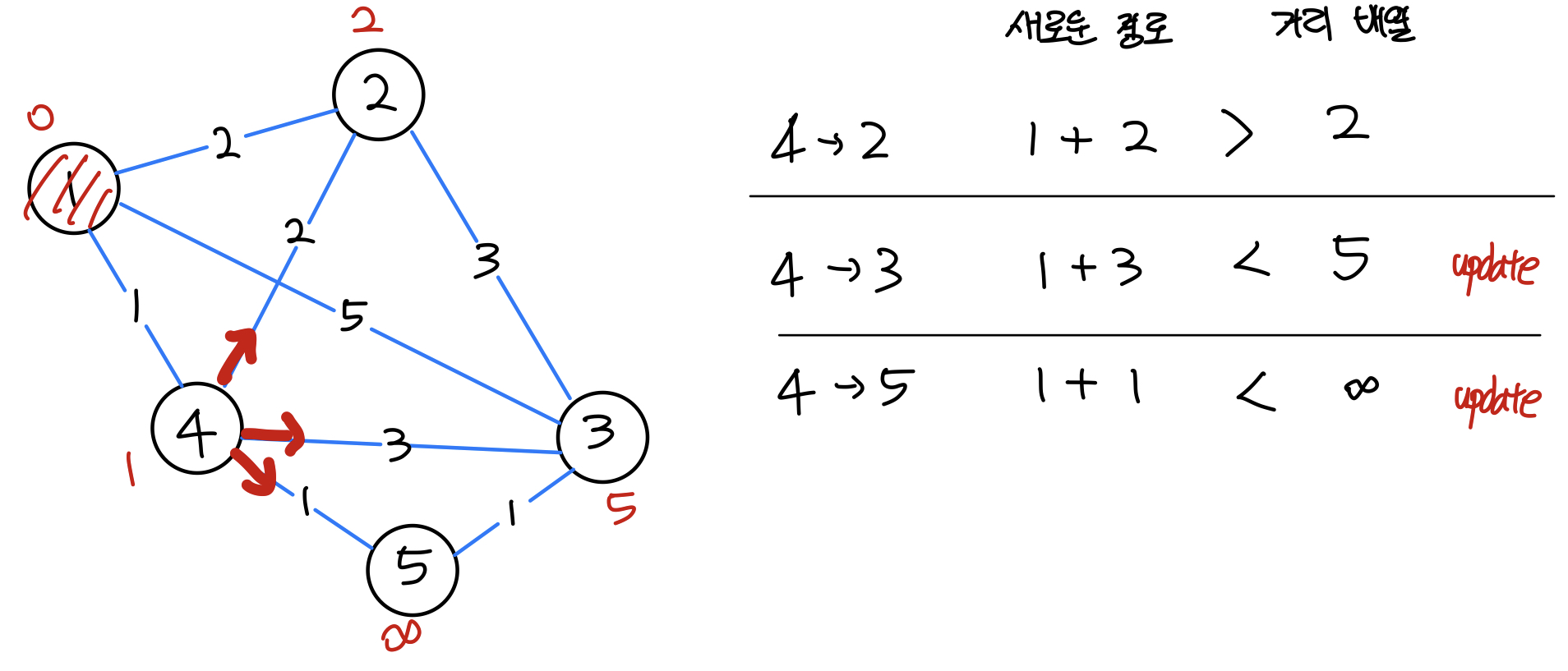
| 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| - | 0 | 2 | 4 | 1 | 2 |
- 현재 우선순위 큐
- (정점, 가중치)
- (2, 2)
- (3, 5)
- (3, 4)
- (5, 2)
[3번째 탐색]
- 가중치가 가장 낮은 2번 노드를 선택한다.
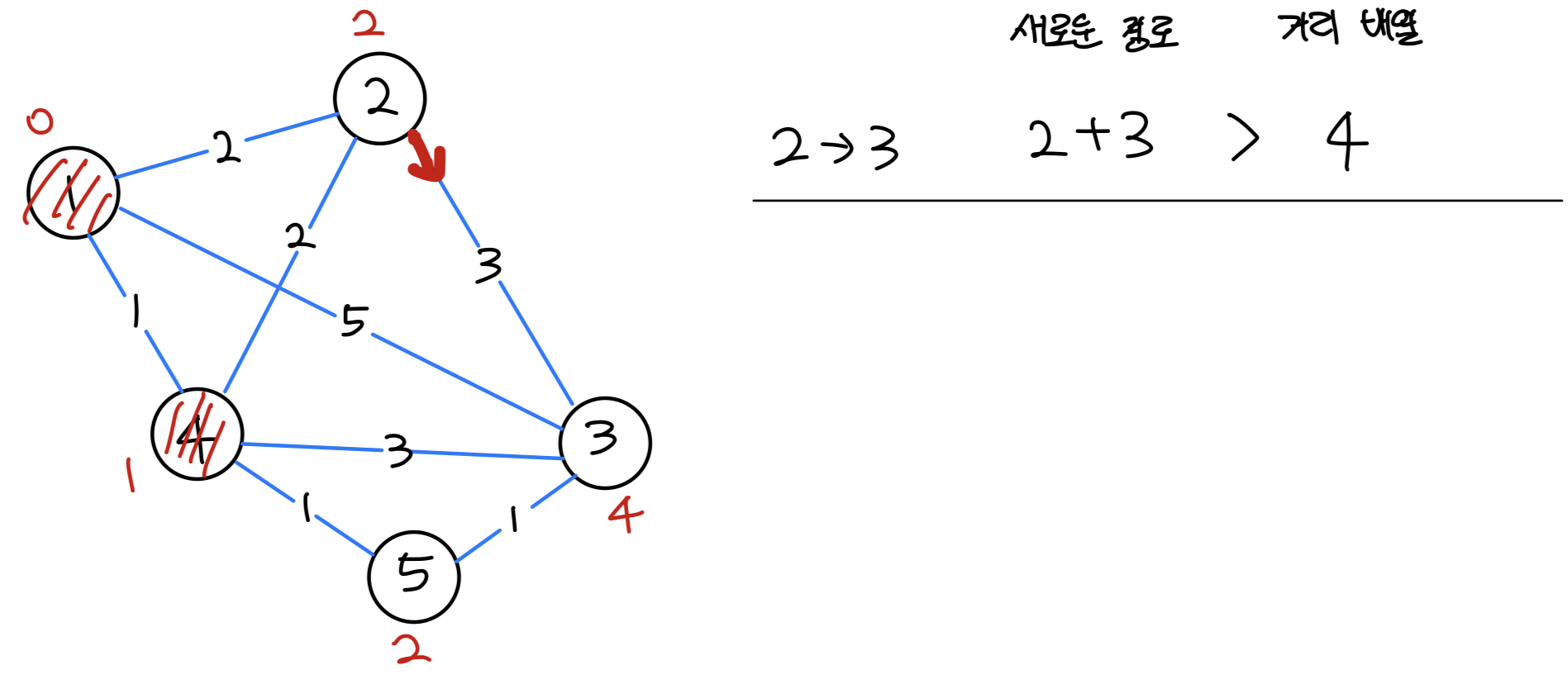
| 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| - | 0 | 2 | 4 | 1 | 2 |
- 현재 우선순위 큐
- (정점, 가중치)
- (3, 5)
- (3, 4)
- (5, 2)
- (3, 4)
[4번째 탐색]
- 가중치가 가장 낮은 5번 노드를 선택한다.
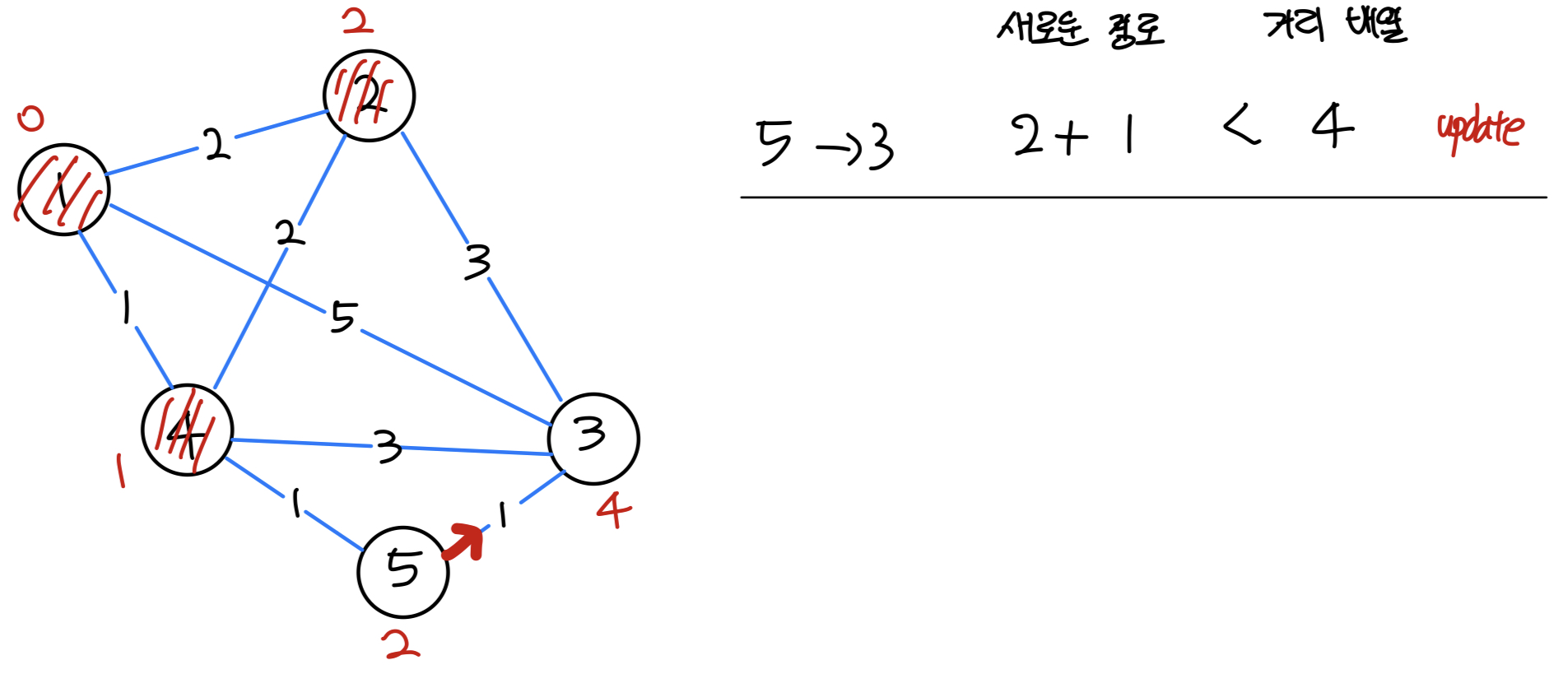
| 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| - | 0 | 2 | 3 | 1 | 2 |
- 현재 우선순위 큐
- (정점, 가중치)
- (3, 5)
- (3, 4)
- (3, 4)
- (3, 3)
[탐색 종료]
- 마지막 3번 노드를 제외하고 모두 방문했으므로 탐색을 종료한다.
- 최종결과는 2번부터 순서대로 2, 3, 1, 2 가 도출된다.
BOJ 1753 - 최단경로 (골드 4)
- 위에서 다루었던 다익스트라 알고리즘을 그대로 구현하면 된다.
PriorityQueue를 사용하였고 그안에 들어갈 자료구조Node클래스를 만들었다.- 우선순위 기준 설정을 위해 Comparable을 상속하여 가중치를 비교하도록 설계한다.
- 방문했던 노드를 기록(
visit[])하는 것은 사실 큰 성능 차이를 보이지는 않지만 혹시 모를 시간 초과를 위해 넣어주자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
import java.io.*;
import java.util.*;
public class Main {
static FastReader scan = new FastReader();
static StringBuilder sb = new StringBuilder();
static int v;
static int e;
static int k;
static int[] distance;
static ArrayList<Node>[] edge;
static boolean[] visit;
public static void main(String[] args) {
input();
solve();
}
static void input() {
v = scan.nextInt();
e = scan.nextInt();
k = scan.nextInt();
distance = new int[v + 1];
Arrays.fill(distance, Integer.MAX_VALUE);
edge = new ArrayList[v + 1];
visit = new boolean[v + 1];
for (int i = 1; i <= v; i++) {
edge[i] = new ArrayList<>();
}
for (int i = 0; i < e; i++) {
int start = scan.nextInt();
int end = scan.nextInt();
int weight = scan.nextInt();
edge[start].add(new Node(end, weight));
}
}
static void solve() {
dijkstra();
for (int i = 1; i <= v; i++) {
if (sb.length() > 0) {
sb.append("\n");
}
if (distance[i] == Integer.MAX_VALUE) {
sb.append("INF");
} else {
sb.append(distance[i]);
}
}
System.out.println(sb.toString());
}
static void dijkstra() {
PriorityQueue<Node> queue = new PriorityQueue<>();
distance[k] = 0;
queue.add(new Node(k, 0));
while (!queue.isEmpty()) {
Node node = queue.poll();
int vertex = node.vertex;
int cost = node.cost;
if (!visit[vertex])
visit[vertex] = true;
for (int i = 0; i < edge[vertex].size(); i++) {
Node node2 = edge[vertex].get(i);
int vertex2 = node2.vertex;
int cost2 = node2.cost;
if (!visit[vertex2] && distance[vertex2] > cost2 + cost) {
distance[vertex2] = cost2 + cost;
queue.add(new Node(vertex2, distance[vertex2]));
}
}
}
}
static class Node implements Comparable<Node> {
int vertex;
int cost;
public Node(int vertex, int cost) {
this.vertex = vertex;
this.cost = cost;
}
@Override
public int compareTo(Node o) {
return cost - o.cost;
}
}
static class FastReader {
.
.
}
}
FastReader
유니온 파인드를 사용하는 문제 리스트
적지 않은 코드 구현량 때문인지 최소 난이도가 골드로 책정되어 있다.
코테에서도 간간히 나오는 알고리즘이므로 잘 익혀놓자.
누군가가 물어본다면
하나의 정점에서 다른 모든 정점으로 가는 최단 경로를 알 수 있는 알고리즘으로 DP의 유형에 속합니다.
This post is licensed under CC BY 4.0 by the author.