TaskScheduler로 배치 작업 개선하기(3/3) - TaskScheduler 도입
들어가며
TaskScheduler를 짚어보고, 왜 도입해야 하는지를 정리해보았다.
이번 포스팅에서는 실제로 TaskScheduler를 적용하면서 어떤 점들을 고려했고, 어떤 기술을 적용했는지 알아보겠다.
대기 중인 쓰레드
@Scheduled와 마찬가지로 예약 시간을 체크하는 쓰레드가 대기한다.
TaskScheduler의 기본 구현체는 ThreadPoolTaskScheduler이다.
쓰레드 풀 설정이 없을 경우 기본적으로 단일 쓰레드로 동작하며, 작업이 몇개가 등록되었든 상관없이 하나의 쓰레드가 순차적으로 처리한다.
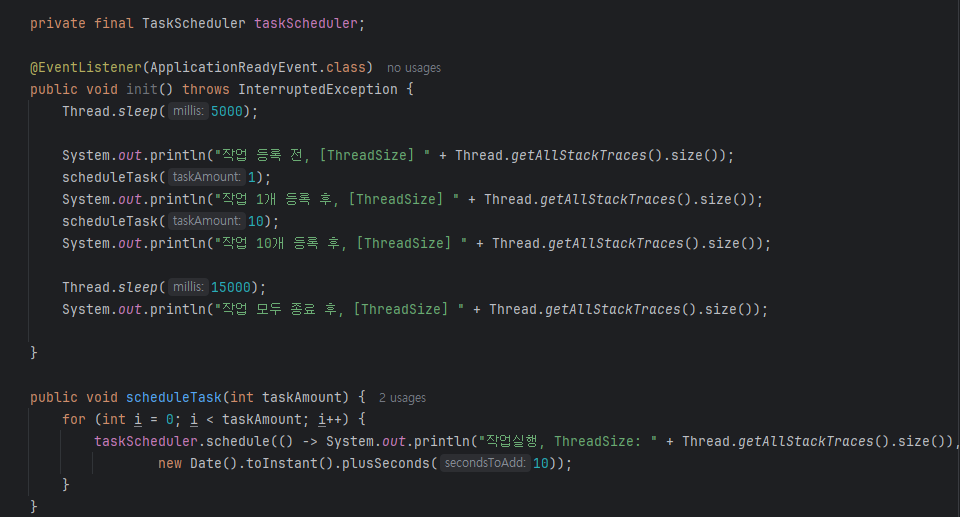
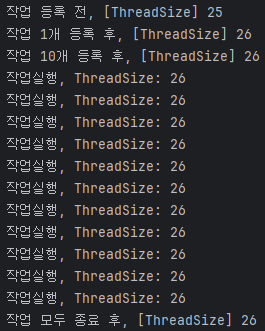
여기서 @Scheduled와 다른 점은 모든 데이터를 가져와서 예약시간이 되었는지 확인하지 않고, 특정 시간에 예약된 작업들만 수행한다는 것이다.
대기하는 쓰레드는 1초마다 모든 데이터를 조회하지 않고, 특정 시간에 등록된 작업만 처리하면 되므로 리소스가 절약된다.
병렬 처리 설정
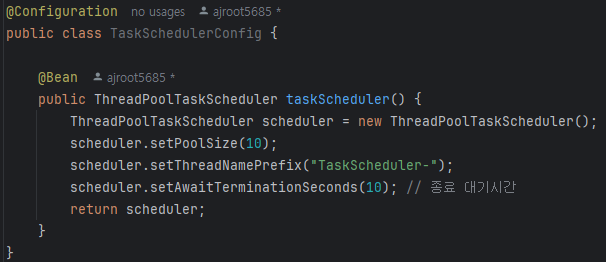
[쓰레드풀 설정]
시스템의 자원을 최대한 끌어쓰기 위해서 쓰레드풀 설정을 추가한다.
[@Async 사용?]
작업들을 비동기로 처리하기 위해 @Async가 필요한 것이 아닌지 의문이 들 수도 있다.
그러나 쓰레드풀을 지정하면 예약 시간을 확인하는 쓰레드가 쓰레드풀의 쓰레드들에게 작업을 하나씩 위임하여 기본적으로 비동기로 동작하게 된다.
이때, @Async를 추가로 설정하면 작업을 위임 받은 쓰레드가 또다시 다른 쓰레드에게 작업을 위임하므로, 비동기 작업이 추가로 필요한게 아니라면 @Async 사용을 하면 안된다.
하나의 작업 당 2개의 쓰레드가 붙게 되는 것이다.
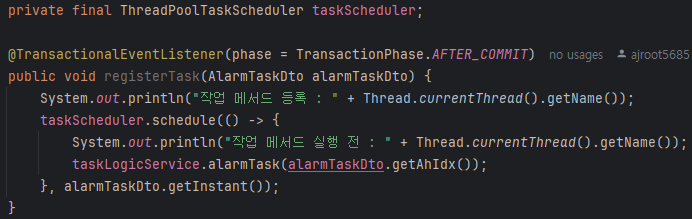
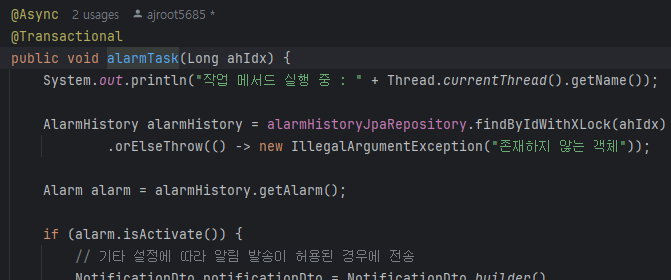
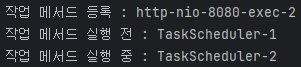
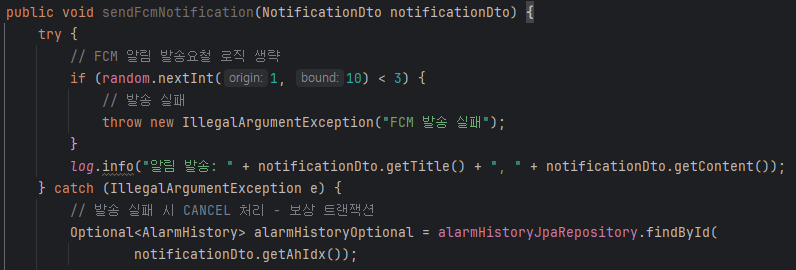
알람 전송 도중 WAS가 종료되면 알람 전송 실패
FCM에 알람 발송을 요청하는 로직을 수행하는 도중에 WAS가 종료되면 전송이 실패되고 기대했던 알림 발송 작업이 수행되지 않을 수 있다.
따라서 gracefulShutdown 설정을 통해 현재 수행 중인 작업이 끝날 때까지 애플리케이션을 대기하도록 설정을 추가한다.
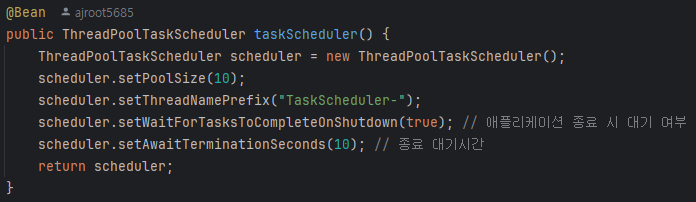
알림 작업 뿐만 아니라, 다른 작업들도 갑자기 종료되면 UX에 악영향을 끼칠 수 있으므로, 애플리케이션 자체에 gracefulShutdown을 설정하는 것을 추천한다.
WAS 재실행 시 예약 작업 재등록
예약된 작업은 별도의 백업 없이 메모리에만 적재된다.
WAS가 종료되면 예약 작업은 모두 사라지기 때문에 재실행 후 다시 등록해주어야 한다.
그러면 DB로부터 알람들을 가져와 재등록을 시켜줘야 하는데, 이미 발송이 끝난 알람과 발송해야 하는 알람을 어떻게 구분할까?
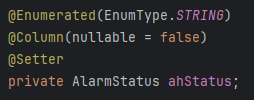
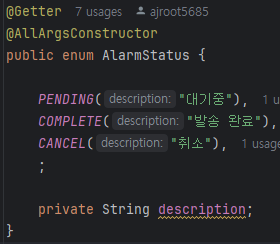
[발송 상태 필드 추가]
알림 내역 엔티티에 발송 상태 필드를 추가하여 구분한다.
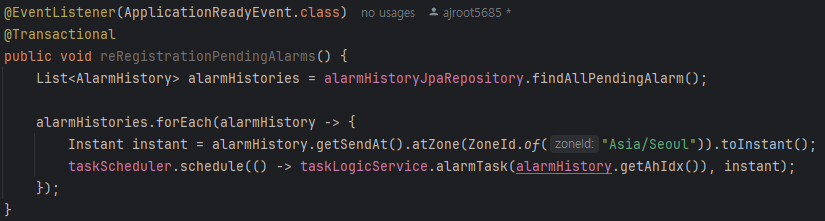
[예약 작업 재등록]
ApplicationReadyEvent를 이용해 WAS가 재실행된 이후에 모든 PENDING 상태인 알림들을 가져와 재등록한다.
각 상태에 대해서는 바로 아래에서 후술한다.
Instant는 반드시 UTC 기준으로 변환되어 설정된다. 따라서 애플리케이션/DB 타임존 등을 체크하고 원하는 시간에 맞게 잘 저장되는지 검증이 필요하다.
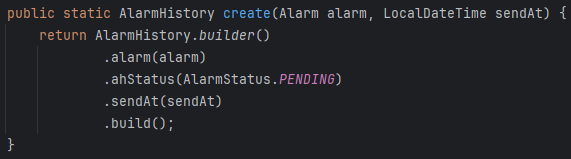
[PENDING]
PENDING 상태는 알림이 발송되어야 하는 상태를 뜻하며, 알림이 생성된 후부터 알림 발송 요청(FCM)을 보낼 때까지 유지된다.
[COMPLETE]
COMPLETE 상태는 알림이 정상적으로 발송된 상태를 뜻하며, 알림 발송 요청을 보낸 후 설정된다.
여기서 유의할 점은 COMPLETE 상태가 무조건 성공을 뜻하는 것이 아니다.
비동기로 알림 발송 요청 로직이 수행되고, 그 결과와 상관없이 COMPLETE 상태로 설정된다.
즉, 알림 발송이 아닌 알림 발송 요청에 성공했다는 뜻이다.
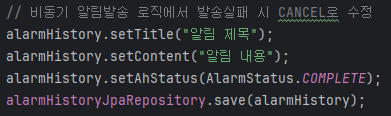
[CANCEL]
위 사진의 주석에서도 볼 수 있듯이 CANCEL 상태는 알림 발송이 실패했을 때 설정된다.
FCM은 알림 발송을 처리할 뿐만 아니라 그 결과도 반환해주기 때문에 알림 발송이 실패했는지 여부를 알 수 있다.
WAS 여러 대이면 중복 발송됨
물론 Task 등록 서버를 따로 두면 문제가 없지만 이 경우는 제외하고 스케일 아웃 등으로 WAS가 여러 대가 된다면 어떻게 될까?
알림 중복 발송이 될 수 있고, 하나의 데이터에 대해 여러 곳에서 수정을 시도하여 일관성이 깨질 수 있다.
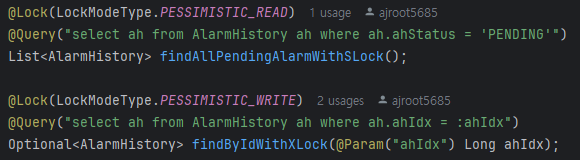
이를 해결하기 위해 스프링의 @Lock 어노테이션과 함께 X-lock을 설정하였다.
Lock을 사용할 때에는 병목이 생기지 않도록 최대한 범위를 줄여야 한다.
알림 발송 요청 로직은 외부와 통신하기 때문에 소요시간이 길고, 이는 Lock 점유시간을 증가시키는 요인이 된다.
때문에 위에서 알림 발송 요청 로직을 비동기로 처리했던 것이다.
아래는 JPA의 @Lock을 사용한 조회메서드와 실제 Lock을 사용한 비즈니스 로직이다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// 1. 예약 작업 로직 실행 시
public void alarmTask(Long ahIdx) {
AlarmHistory alarmHistory = alarmHistoryJpaRepository.findByIdWithXLock(ahIdx)
.orElseThrow(() -> new IllegalArgumentException("존재하지 않는 객체"));
.
.
}
// 2. 알림 발송 실패 시
catch (IllegalArgumentException e) {
Optional<AlarmHistory> alarmHistoryOptional = alarmHistoryJpaRepository.findByIdWithXLock(
notificationDto.getAhIdx());
.
.
}
// 3. WAS 재실행으로 인해 알람 예약 재등록 시
public void reRegistrationPendingAlarms() {
List<AlarmHistory> alarmHistories = alarmHistoryJpaRepository.findAllPendingAlarmWithSLock();
.
.
}
기타 - 비동기 알림 발송 요청
짧게 넘어갔지만 알림 발송이 실패하면 보상 트랜잭션을 수행하게 된다.
그런데 이 보상 트랜잭션은 절대 실패하지 않을까?
당연히 아니므로, 별도로 핸들링 로직이 필요하다.
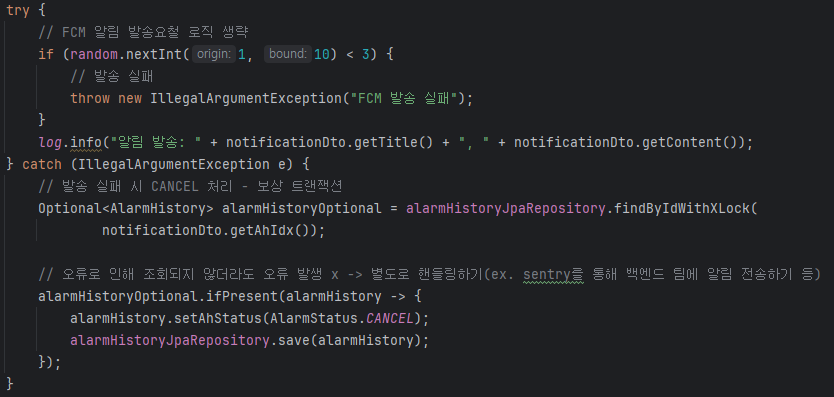
- 위 이미지처럼 오류가 발생하더라도 추가 처리는 하지않고, 개발자에게 알리기만 한다.
- 유연하게 대처가 가능하므로, 오류 발생이 서비스에 치명적이지 않을때 좋은 방법이다.
- 보상 트랜잭션 큐를 구축하여 직접 트랜잭션을 수행하지 않고 이벤트를 등록한다.
- 보상 트랜잭션의 실패에 대해 또다시 보상 트랜잭션을 수행하는 것은 밑빠진 독에 물붓기와 같다.
- 이벤트를 통해 처리하면, 일시적인 장애나 락 타임아웃으로 인한 오류를 방지할 수 있다.