가상 면접 사례로 배우는 대규모 시스템 설계 기초
들어가며
백엔드 개발자라면 반드시 읽어야 하는 도서 중 하나인 책이다.
흔히 발생하는 문제들에 대한 해결책인 디자인 패턴처럼 대규모 시스템을 설계하는 데 있어 가이드라인을 제시해준다.
백엔드 개발자는 단순한 코딩 역량보다는 상황에 적합한 기술 선택과 적합한 시스템을 설계하는 역량이 중요하다고 생각한다.
꼭 읽어볼 것을 추천하며, 일부 내용을 소개한다.
5장. 안정 해시 설계
대규모 트래픽을 처리할 때, 대부분의 경우 수평적 확장으로 여러 대의 서버를 둔다.
이때 안정 해시를 사용해 요청 또는 데이터를 각 서버에 균등하게 나눈다.
안정 해시도 처음부터 완벽한 기술은 아니었다.
해시 키 재배치 문제
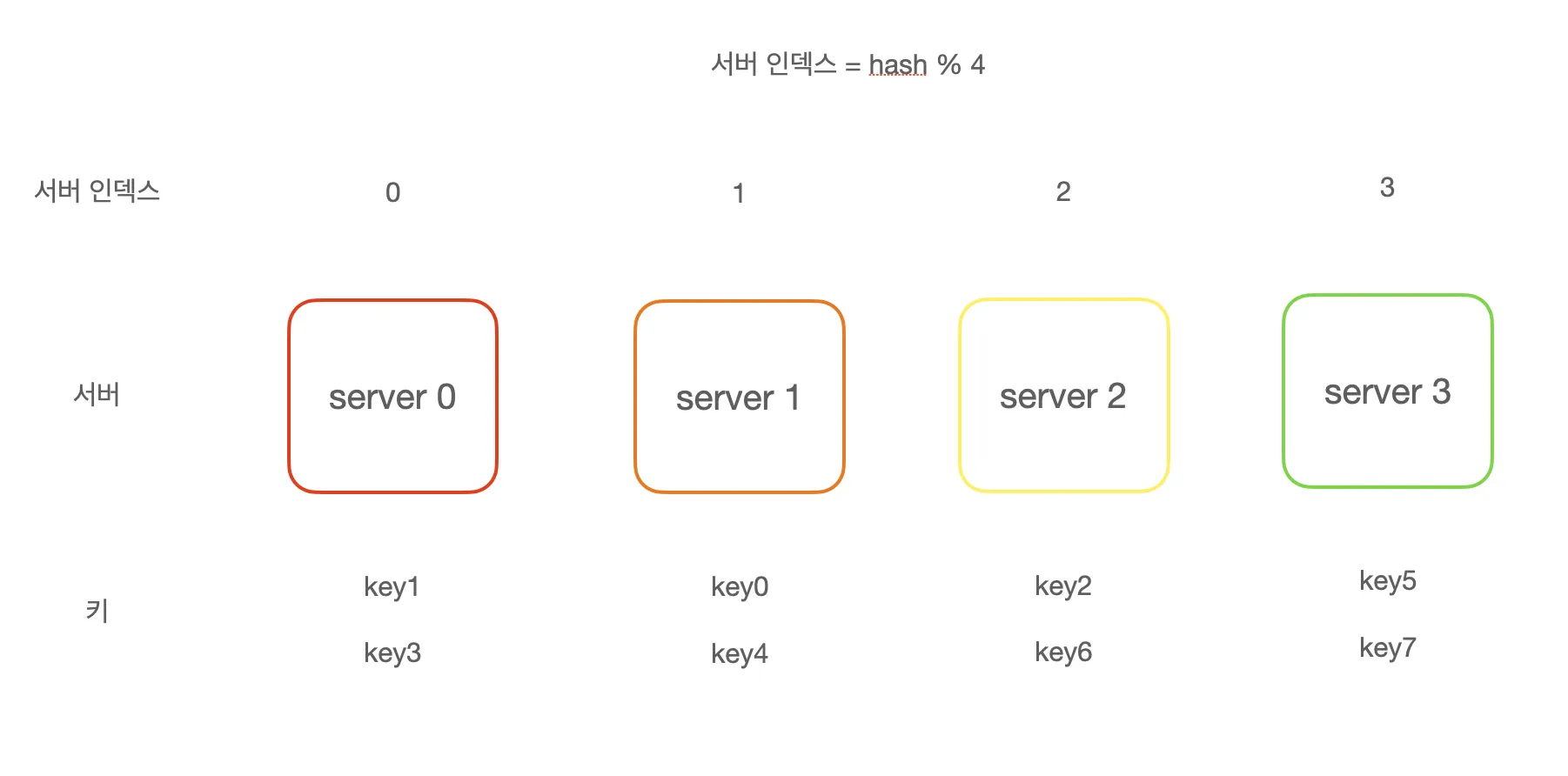
N개의 캐시 서버가 있을 때 부하를 균등하게 나누는 보편적 방법은 다음과 같은 해시 함수를 사용하는 것이다.
1
serverIndex == hash(key) % N
서버가 추가되거나 기존 서버가 삭제될 때 위와 같은 해시 함수는 문제를 일으킬 수 있다.
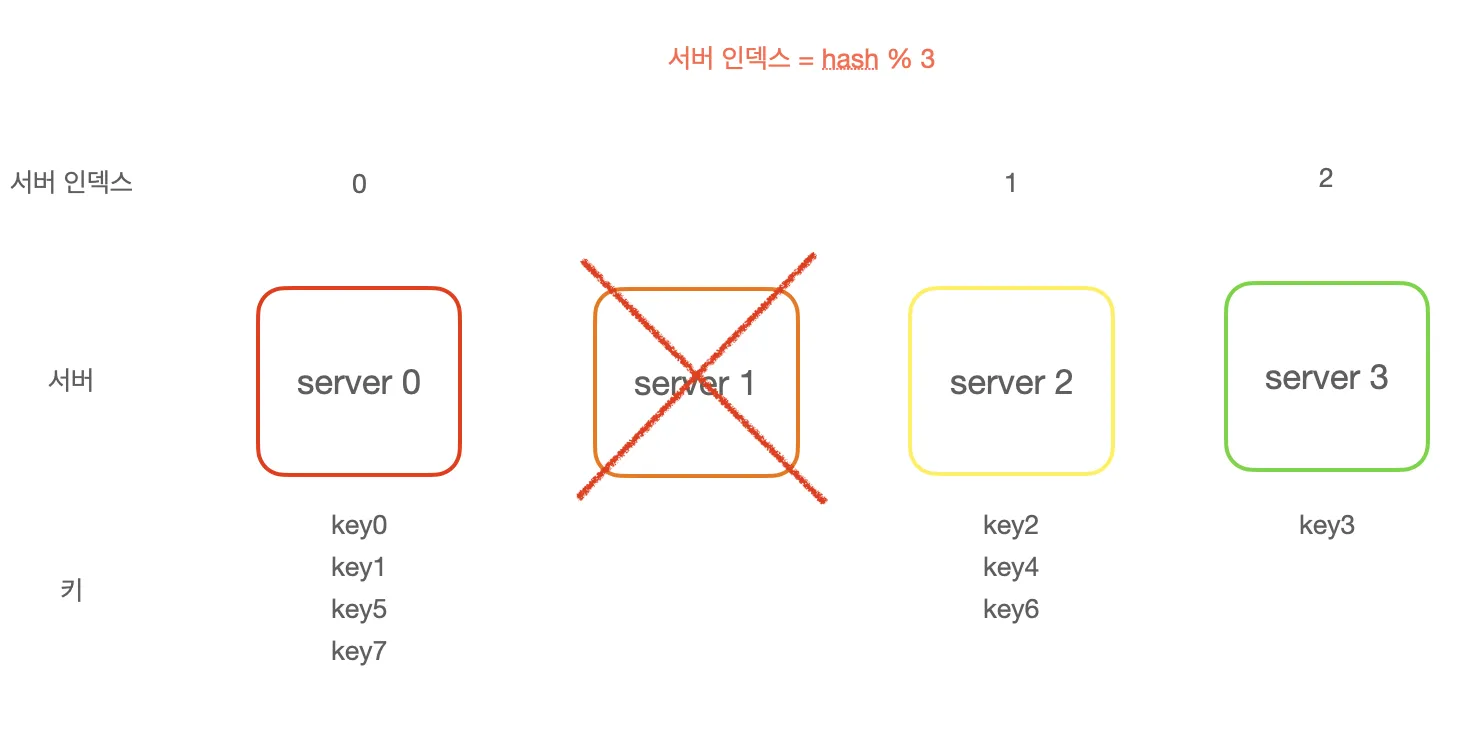
1번 서버가 장애를 일으켜 동작을 중단하면 서버 풀의 크기가 3으로 변하고 대부분의 키가 재분배된다.
그 결과 대규모 캐시 미스가 발생하여 일시적으로 사용자는 긴 지연시간을 체감하게 된다.
안정 해시는 해시 공간을 링 형태로 만들어 이 문제를 해결했다.
기타 문제
위의 문제 외에도 안정 해시는 다음과 같은 문제를 지니고 있었다.
- 파티션의 크기를 균등하게 유지할 수 없다.
- 키의 균등 분포를 달성하기 어려워 특정 서버에 키가 몰릴 수 있다.
책에서는 가상 노드를 소개하며 위 두 가지의 문제를 해결했다.
7장. 분산 시스템을 위한 유일 ID 생성기 설계
우리는 보통 하나의 DB만 사용하며 각 테이블의 pk는 auto_increment로 관리한다.
9백경이라는 수를 저장할 수 있지만, 실제로는 이 데이터가 쌓이기 전에 커넥션이 부족해지게 될 것이다.
그래서 분산 DB 서버를 구축한다면 어떻게 pk의 유일성을 보장할 수 있을까?
다중 마스터 복제
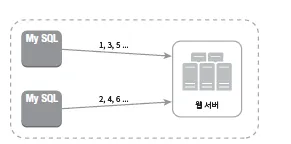
동일하게 auto_increment 기능을 활용하지만, 1씩 증가하는 것이 아니라 서버의 개수만큼 증가시킨다.
하지만 이는 규모를 늘리기 어렵고, 서버를 추가/삭제할 대 잘 동작하도록 만들기 어렵다.
UUID
충돌 가능성이 지극히 낮은 32자 16진수 문자열이다.(하이픈 포함 36자)
단순하지만, 128비트로 길고, 시간순으로 정렬할 수 없는 무작위성을 지녔으며, 숫자가 아닌 값이 포함되어 성능에 영향을 미친다.
티켓 서버
auto_increment 기능을 갖추어 id 값을 발급해주는 중앙 집중형 서버이다.
하지만 언제나 중앙 집중형은 Single Point Of Failure가 된다는 것에 주의해야 한다.
트위터 스노플레이크 접근법
사용자가 많은 트위터는 위의 방법들에 한계를 느끼고 독창적인 ID 생성 기법을 만들어냈다.

64비트를 사용해 32개의 데이터센터와 데이터센터 당 32개의 서버를 구분할 수 있다.
가장 정답에 가까운 기법이라 볼 수 있다.
11장. 뉴스 피드 시스템 설계
뉴스 피드란 사용자가 관심 있는 콘텐츠를 자동으로 받아볼 수 있는 콘텐츠 스트림이다.
뉴스 피드에는 크게 2가지 기능이 필요하다.
- 자신의 새로운 포스팅을 친구들에게 알리는 피드 발행
- 새로운 피드를 읽는 피드 읽기
피드 메커니즘은 여러 팬아웃 기법을 적용하여 상황에 맞게 구현한다.
쓰기 시점 팬아웃
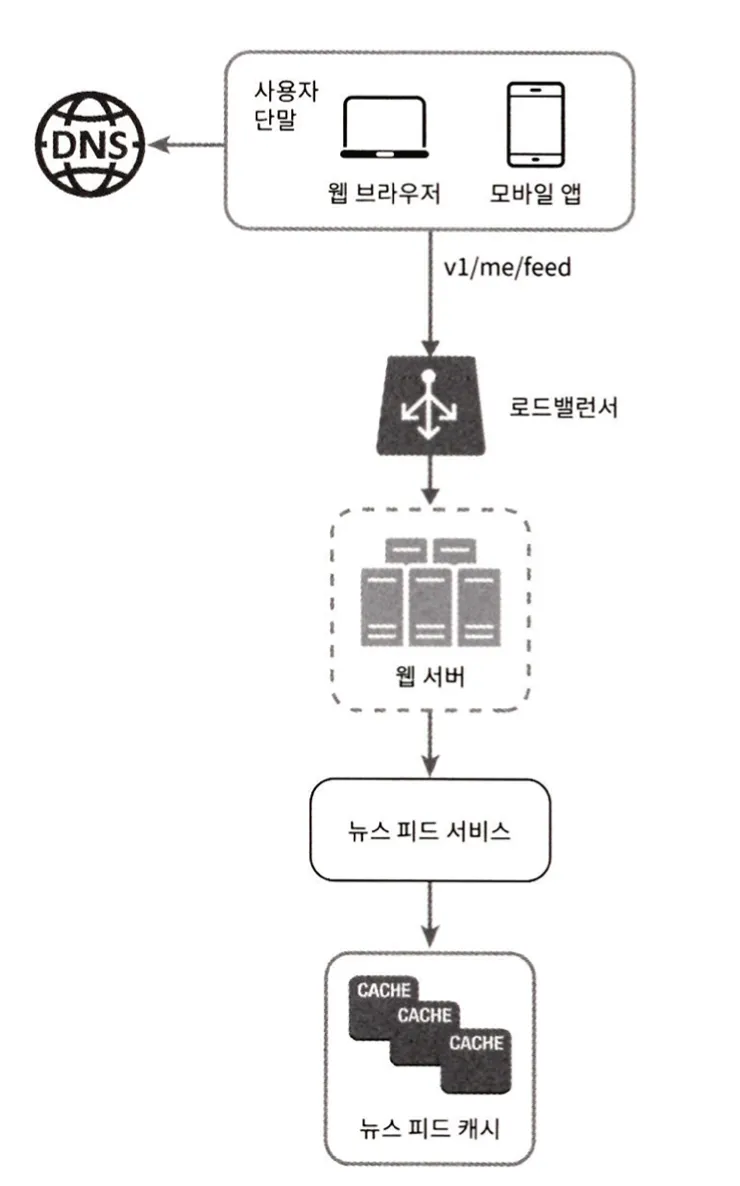
새로운 포스팅을 기록하는 시점에 뉴스 피드를 갱신한다.
장점
- 피드를 읽는 사람은 캐시에서 가져가기만 하면 되므로 지연 시간이 짧다.
단점
- 친구가 많은 사용자라면 모두의 뉴스 피드를 갱신하는 데 많은 시간이 소요된다.
- 서비스를 자주 이용하지 않는 사용자의 피드까지 갱신해야 하므로 컴퓨팅 자원이 낭비된다.
읽기 시점 팬아웃
피드를 읽어야 하는 시점에 뉴스 피드를 갱신한다.
장점
- 비활성화된 사용자 문제가 해결된다.
- 핫키 문제도 생기지 않는다.
단점
- 뉴스 피드를 읽는 데 많은 시간이 소요될 수 있다.
결합
두 가지 방법을 결합하여 대부분의 사용자에게는 쓰기 시점 팬아웃을, 친구가 많은 사용자에게는 읽기 시점 팬아웃을 적용한다.
14장. 유튜브 설계
이 장에서는 비디오를 업로드하고 트랜스코딩하는 아키텍처를 주로 설명한다.
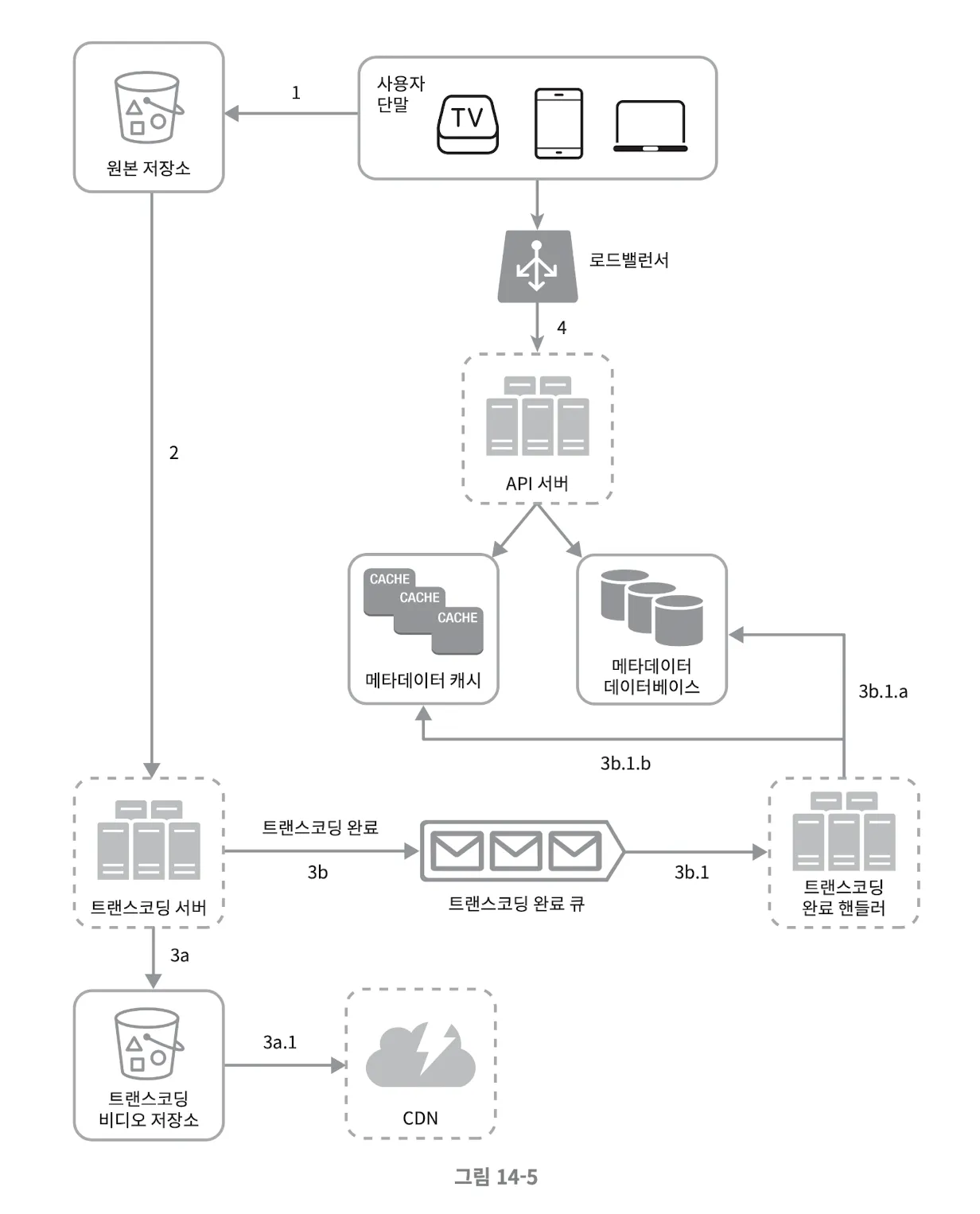
비디오 업로드 프로세스
- 비디오를 원본 저장소에 업로드한다.
- 트랜스코딩 서버는 원본 저장소에서 해당 비디오를 가져와 트랜스코딩을 시작한다.
- 트랜스 코딩이 완료되면 아래 절차를 병렬적으로 수행한다.
- 완료된 비디오를 트랜스코딩 비디오 저장소로 업로드한다.
- 트랜스코딩이 끝난 비디오를 CDN에 올린다.
- 트랜스코딩 완료 이벤트를 트랜스코딩 완료 큐에 넣는다.
- 완료 핸들러가 이벤트 데이터를 큐에서 꺼낸다.
- 완료 핸들러가 메타데이터 데티어베이스와 캐시를 갱신한다.
- 완료 핸들러가 이벤트 데이터를 큐에서 꺼낸다.
- 완료된 비디오를 트랜스코딩 비디오 저장소로 업로드한다.
- API 서버가 단말에게 비디오 업로드가 끝나서 스트리밍 준비가 되었음을 알린다.
고려사항
- 여러 비트레이트와 포맷으로 저장하여 사용자 네트워크 상황에 따라 다른 화질의 비디오를 제공해야 한다.
- 트랜스코딩 작업은 리소스가 많이 드는 작업이므로 별도의 서버에서 수행하는 것이 적절하다.
비디오 스트리밍 적용
현재 나는 영상 스트리밍이 필요한 프로젝트를 진행하고 있는데, 위와 유사한 방식으로 설계했다.
위의 고려사항이 걸림돌이 되었는데, 다음과 같이 해결했다.
네트워크 상황을 고려한 다른 화질의 비디오 제공
HLS(HTTP Live Streaming)은 Adaptive Streaming 방식을 사용해서, 네트워크 상황에 따라 클라이언트가 자동으로 다른 화질의 비디오를 선택해 요청한다.
HLS 영상 데이터는 마스터 파일, 화질에 대한 마스터 파일, 영상 데이터 조각(.ts)으로 이루어진다.
서버에서는 다양한 화질에 대한 영상 데이터를 만들어두기만 하면 클라이언트에서 알아서 화질을 조정할 수 있어 편리한 프로토콜이다.
트랜스코딩 작업
대부분의 사이드 프로젝트가 그렇듯, 추가적인 서버를 두는 것은 비용, 관리 측면에서 부담스럽다.
책에서는 복잡한 트랜스코딩 서버 설계를 설명하고 있는데, 나는 AWS의 관리형 서비스인 MediaConvert를 사용하여 해결했다.
영상 스트리밍 아키텍처에 도움이 되도록 추후에 구성한 아키텍처를 소개해보겠다.