JWT RTR 도입 (1/2) - Redis 개념 정리
Posted
By ROOT
14 min read
Redis란
- REmote DIctionary Server 의 약자다.
Key - Value 구조의 비정형 데이터를 저장하고 관리하기 위한 오픈소스 기반의 NoSQL DBMS
- 데이터베이스 뿐만 아니라 캐시, 메세지 브로커로도 사용되며 인메모리 데이터 구조를 가진 저장소다.
빠른 속도, 편리한 기능으로
Key-Value 저장소중 가장 순위가 높다.
인메모리 데이터 구조
- 디스크가 아닌 주 메모리(메인 메모리)에 모든 데이터를 보유하고 있는 구조다.
흔히 아는
MySQL,PostgreSQL,MongoDB등은 디스크에 데이터를 저장한다.
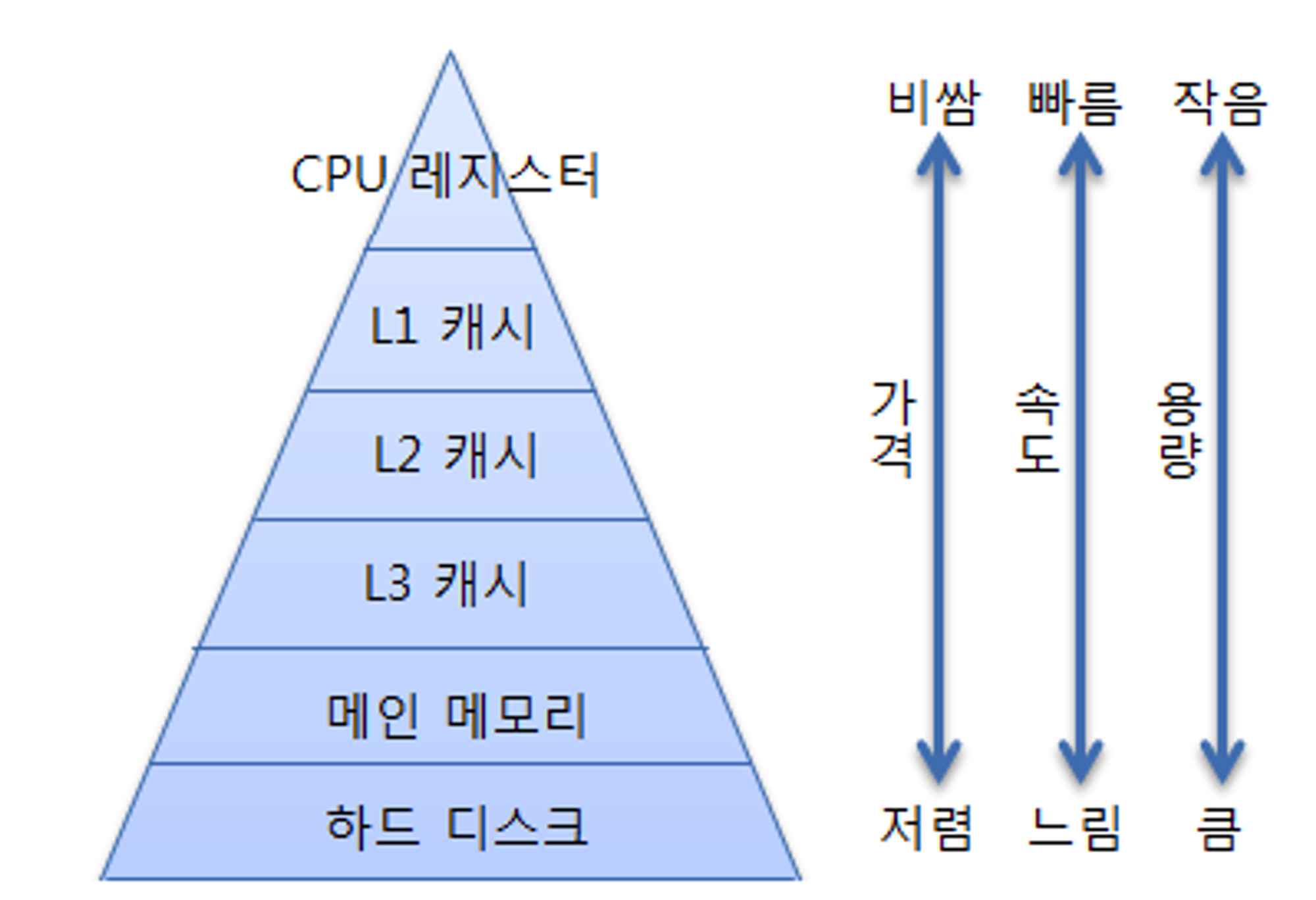
- 이해를 돕기 위해 맥북 에어 m2 모델의 스펙을 예로 들어보자.
- 캐시메모리(SRAM) : 16MB
- DRAM : 8GB
- SSD : 256GB
- 캐시메모리가 L1, L2, L3 캐시 계층, DRAM이 메인메모리 계층, SSD가 하드디스크 계층에 속한다.
사실 CPU 레지스터에도 SRAM이 사용된다.
- 레디스가 인메모리 데이터 구조라는 것은 말그대로 메인메모리 계층에 데이터를 저장한다는 것이다.
- 때문에 알고리즘을 잘 짜서 성능이 좋은 것이 아니라 물리적으로 빠른 저장소를 사용하기 때문에 성능이 좋은 것이다.여담으로 캐시 계층에 데이터를 저장하는 DB는 진짜 빠를 것이라 생각할 수 있지만, 캐시 계층은 CPU에 의해 자동으로 관리되며, DB 또는 애플리케이션이 제어할 수 없기 때문에 캐시 계층을 저장소로 활용하는 DB는 없다.
단점
- 메모리를 사용하므로 휘발성이다.
- DB 서버 전원이 오류 등으로 인해 갑자기 꺼져버리면 데이터가 모두 삭제된다.
- DB시스템의 핵심 속성인
ACID중Durability(지속성)을 위반한다고 볼 수 있다.
- 데이터가 램 용량보다 많은 경우 가상메모리를 사용하여 오히려 속도가 줄어들 수 있다.
자세한 내용은
Page Fault를 공부해보자.
특징
Key-Value구조이기 떄문에 쿼리를 사용할 필요가 없다.- 메모리에서 데이터를 처리하기 때문에 속도가 빠르다.
- 한 번에 하나의 명령만 처리할 수 있는 싱글 쓰레드이다.
- 따라서 처리 시간이 긴 명령어가 들어오면 그 뒤의 명령어들도 대기 시간이 길어지는
처리 지연이 발생한다.
- 따라서 처리 시간이 긴 명령어가 들어오면 그 뒤의 명령어들도 대기 시간이 길어지는
코드로 구현한 Redis
1
private final Map<String, Object> hashMap = new HashMap<>();
- 자바에서
Map구조가 레디스와 가장 비슷하다고 볼 수 있다.
Redis를 사용하는 이유
- 위 코드처럼 데이터를 저장하는 방법이 존재하는데 레디스를 사용하는 이유가 뭘까?
- 멀티쓰레딩
- 위의 코드는 단순하지만 동시성을 보장하지 못해
race condition이 발생할 수 있다. - 레디스는 멀티쓰레딩을 지원하여 여러 클라이언트의 동시 접근을 효율적으로 처리하도록 설계되었다.
- 위의 코드는 단순하지만 동시성을 보장하지 못해
- 다양한 데이터 구조 지원
- 레디스는
HashMap뿐만 아니라String,Bitmap,List,Set,Sorted Set,Hash등 다양한 데이터 구조를 지원하므로 특정 데이터 타입에 한정되지 않고 자유롭게 사용할 수 있다.
- 레디스는
- 데이터 저장소 분리
- 비즈니스 로직과 함께 데이터를 저장하면 접근속도는 빠르겠지만 다른 서버에서의 요청까지 처리해야 할 수 있다.
- 때문에 이름처럼 원격 서버로 분리시켜 여러 서버의 데이터 접근 요청을 처리하는 것이 성능 상 좋다.
- 다양한 기능 제공
- 백업처럼 주기적으로 스냅샷을 저장하여 복구할 수 있는
퍼시스턴트, 고가용성을 위한복제, 복제와 스케일 아웃을 제공하는클러스터링등 많은 기능을 제공하여 빠르기 때문에 RDB처럼 사용하는 사람들도 있다.뒤에서 간단하게 소개하겠다.
- 백업처럼 주기적으로 스냅샷을 저장하여 복구할 수 있는
캐시 서버
- 레디스는 메모리에 저장하여 오류가 발생하면 데이터가 삭제된다고 했다.
- 그래서 레디스를 주로 캐시 서버로 활용하는 경우가 많다.
- 어떤 방식으로 활용하는지 짧게 소개하겠다.
[Look aside cache 패턴]
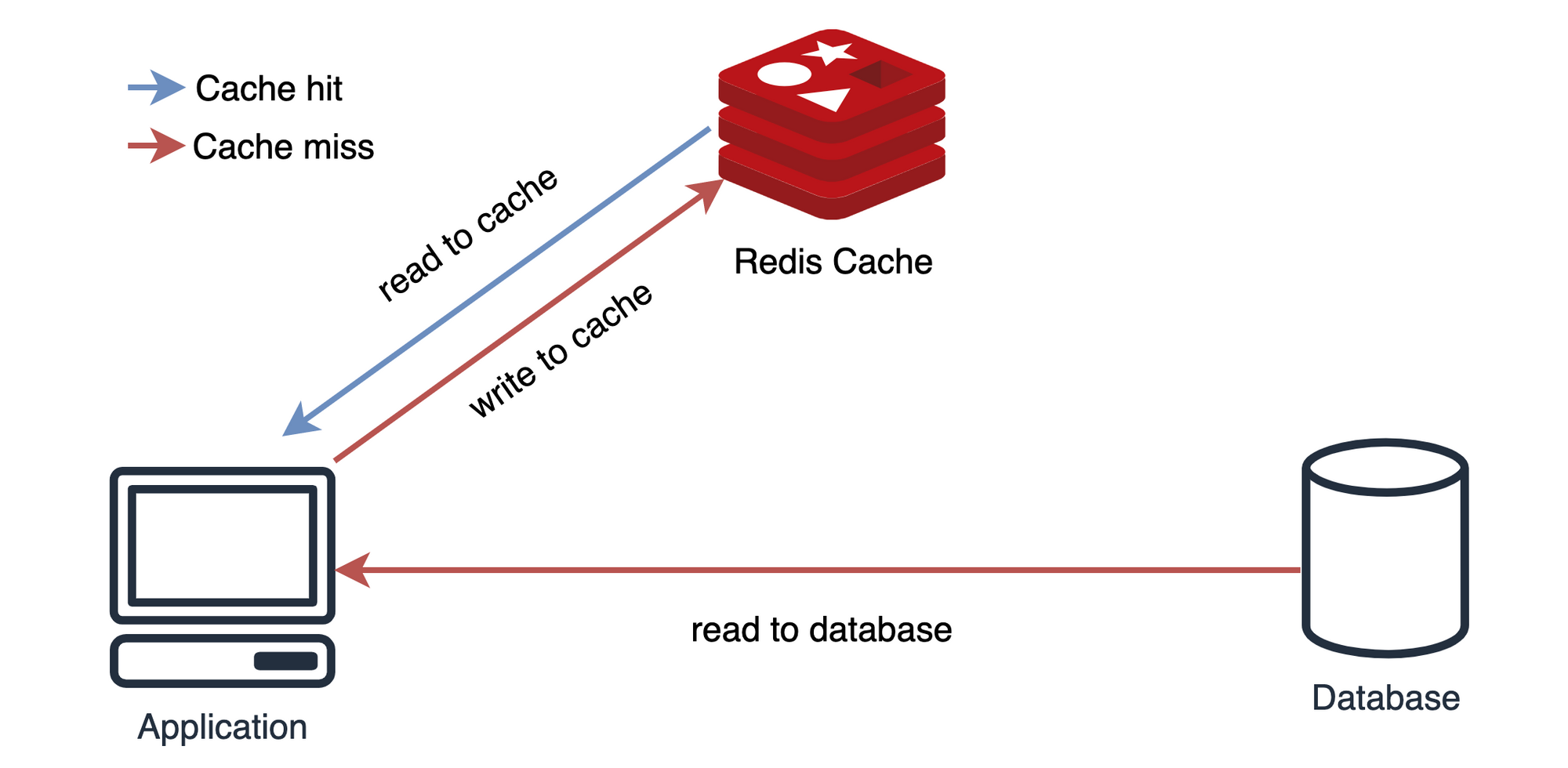
- 클라이언트가 데이터를 요청한다.
- 웹서버는 데이터가 존재하는지 캐시 서버에 먼저 확인한다.
- 캐시 서버에 데이터가 있으면 DB에 데이터를 조회하지 않고 캐시 서버에 있는 결과값을 클라이언트에게 바로 반환한다.(
hit) - 캐시 서버에 데이터가 없으면 DB에 데이터를 조회하여 캐시 서버에 저장하고 결과값을 클라이언트에게 반환한다.(
miss)
예시 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
import redis
import sqlite3
# Redis 클라이언트 설정
redis_client = redis.StrictRedis(host='localhost', port=6379, db=0)
# SQLite 클라이언트 설정
db = sqlite3.connect('database.db')
cursor = db.cursor()
def get_data(key):
# 캐시에서 데이터 조회
cached_data = redis_client.get(key)
if cached_data:
# hit
return cached_data
else:
# miss
# 데이터 저장소에서 데이터 조회
cursor.execute('SELECT value FROM data WHERE key=?', (key,))
row = cursor.fetchone()
if row:
data = row[0]
# 캐시에 데이터 저장
redis_client.set(key, data)
return data
else:
return None
def set_data(key, value):
# 데이터 저장소에 데이터 저장
cursor.execute('INSERT OR REPLACE INTO data (key, value) VALUES (?, ?)', (key, value))
db.commit()
# 예시 사용 코드
set_data('key1', 'value1')
print(get_data('key1'))
[Write Back 패턴]
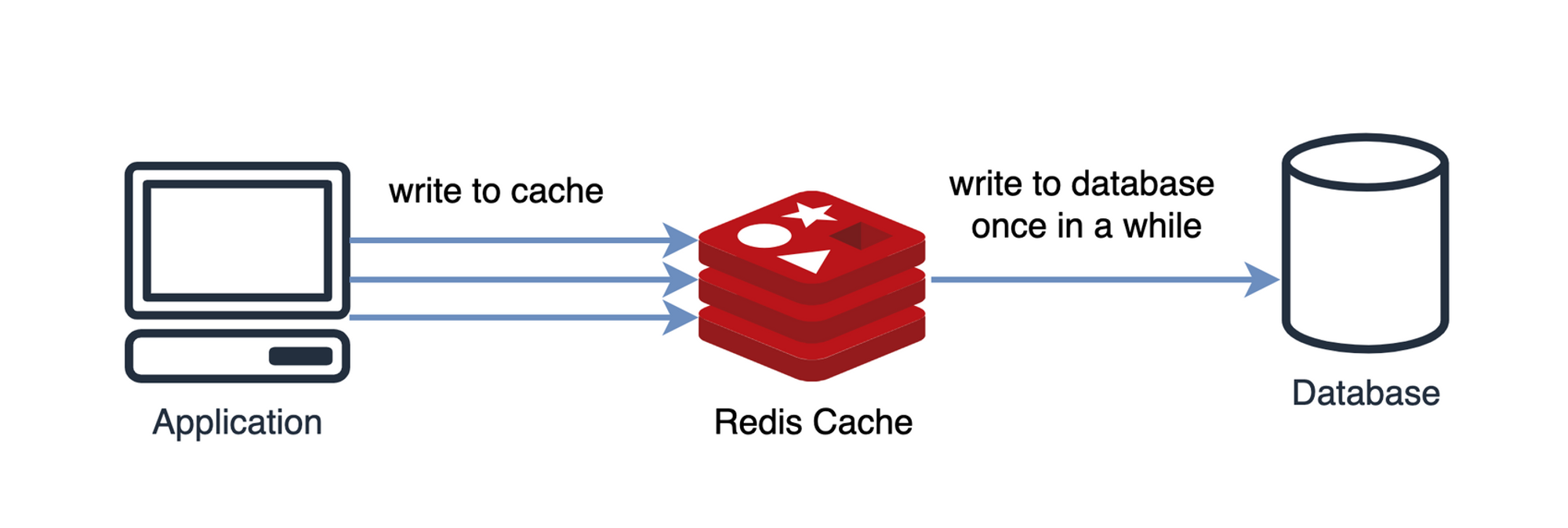
- 웹서버는 모든 데이터를 캐시 서버에 저장
- 캐시 서버에 특정 시간 동안 데이터가 저장된다.
- 일정 주기마다 캐시 서버에 있는 데이터를 DB에 저장한다.
- DB에 저장된 데이터는 캐시 서버에서 삭제한다.
- 나중에 비동기적으로 쓰기 작업을 수행하므로 성능이 좋아진다.
- 하지만 만약 캐시 서버에 데이터가 머무르는 동안 장애가 발생하면 해당 데이터는 손실될 수 있다.
예시 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
import redis
import sqlite3
import threading
import time
# Redis 클라이언트 설정
redis_client = redis.StrictRedis(host='localhost', port=6379, db=0)
# SQLite 클라이언트 설정
db = sqlite3.connect('database.db')
cursor = db.cursor()
# 주기적으로 캐시 데이터를 저장소에 반영
def flush_cache():
while True:
time.sleep(60) # 1분 주기
keys = redis_client.keys('*')
for key in keys:
data = redis_client.get(key)
if data:
cursor.execute('INSERT OR REPLACE INTO data (key, value) VALUES (?, ?)', (key.decode('utf-8'), data.decode('utf-8')))
db.commit()
# 별도의 스레드로 캐시 플러시 함수 실행
threading.Thread(target=flush_cache, daemon=True).start()
def get_data(key):
# 캐시에서 데이터 조회
cached_data = redis_client.get(key)
if cached_data:
# hit
return cached_data
else:
# miss
# 데이터 저장소에서 데이터 조회
cursor.execute('SELECT value FROM data WHERE key=?', (key,))
row = cursor.fetchone()
if row:
data = row[0]
# 캐시에 데이터 저장
redis_client.set(key, data)
return data
else:
return None
def set_data(key, value):
# 캐시에 데이터 저장
redis_client.set(key, value)
# 예시 사용 코드
set_data('key1', 'value1')
print(get_data('key1'))
Redis가 지원하는 다양한 기능들
- 넘어가도 되는 살짝 깊은 부분이지만 어떤 기능이 있는지 간단하게 살펴보겠다.
[Persistence]
- RDB 스냅샷을 저장한다.
여기서 RDB는 관계형 DB가 아니라
Redis database를 뜻한다. - 주기적을 메모리의 데이터를 디스크에 저장한다.
- 예기치 못한 오류로 시스템이 종료되었을 때 디스크에 저장된 파일로부터 복구가 가능하다.
- 하지만 마지막 스냅샷 이후의 데이터는 손실될 수 있다.
[복제]
- 고가용성을 달성할 수 있다.
- 오랜 시간 동안 오류 발생 등으로 시스템이 멈추지 않고 작동할 수 있다.
Master-Slave구조를 기반으로 한다.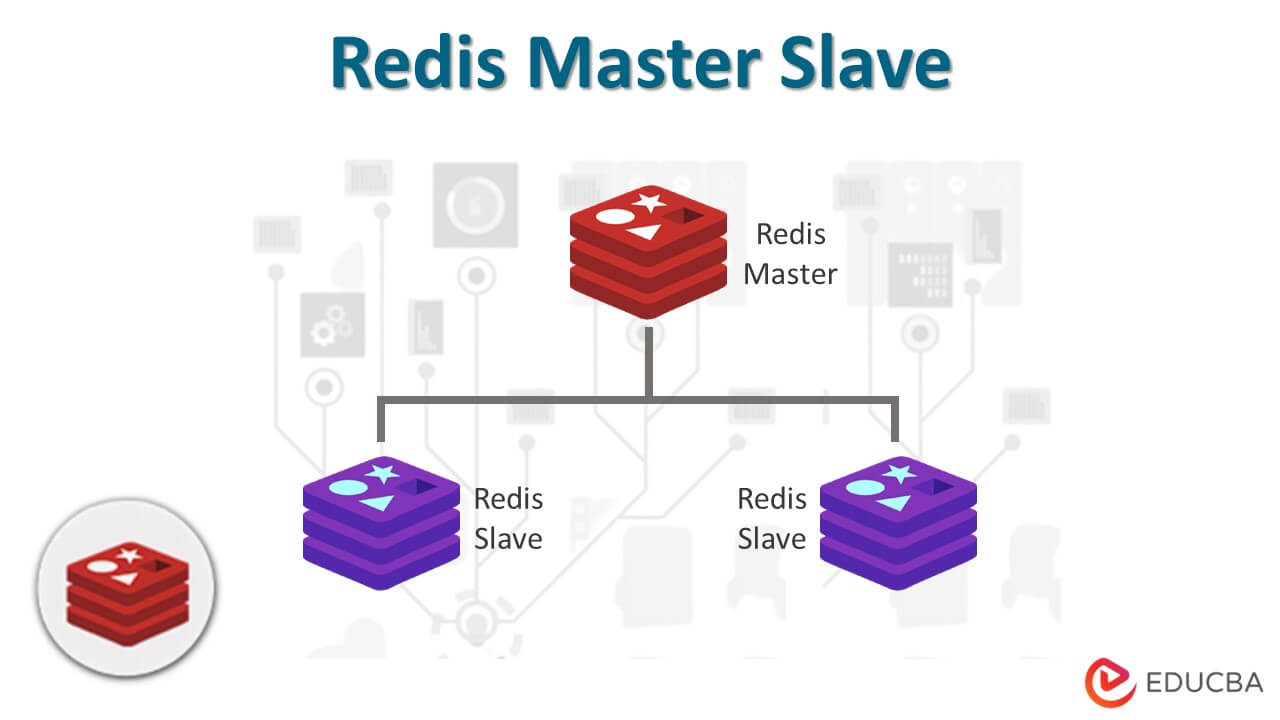
- Master Node
- 쓰기 작업을 담당한다.
- Slave Node에게 읽기 작업을 나눠주어 읽기 부하를 분산시킨다.
- Slave Node
- Master Node에게 할당받은 읽기 작업을 수행한다.
- Slave Node는 비동기적으로 마스터 노드의 데이터를 복제한다.
- Master Node
- 오류 발생 시
- Slave Node는 여러 개이므로 하나의 Node가 멈춰도 다른 Node가 남아있으므로 전체 시스템은 멈추지 않는다.
- 그동안 다른 Slave Node가 새로 생긴다.
자동 failover- Master Node는 1개이므로 문제가 발생하면 전체 시스템이 멈출 수 있다.
자동 failover기능은 이때 Slave Node 중 하나를 Master Node로 승격시켜 전체 시스템이 마비되지 않도록 한다.
[클러스터]
- 데이터를 노드에 분산 저장하여 확장성과 가용성을 높이는 기능이다.
위의 복제 기능에 더해
스케일 아웃기능을 제공한다.스케일 아웃
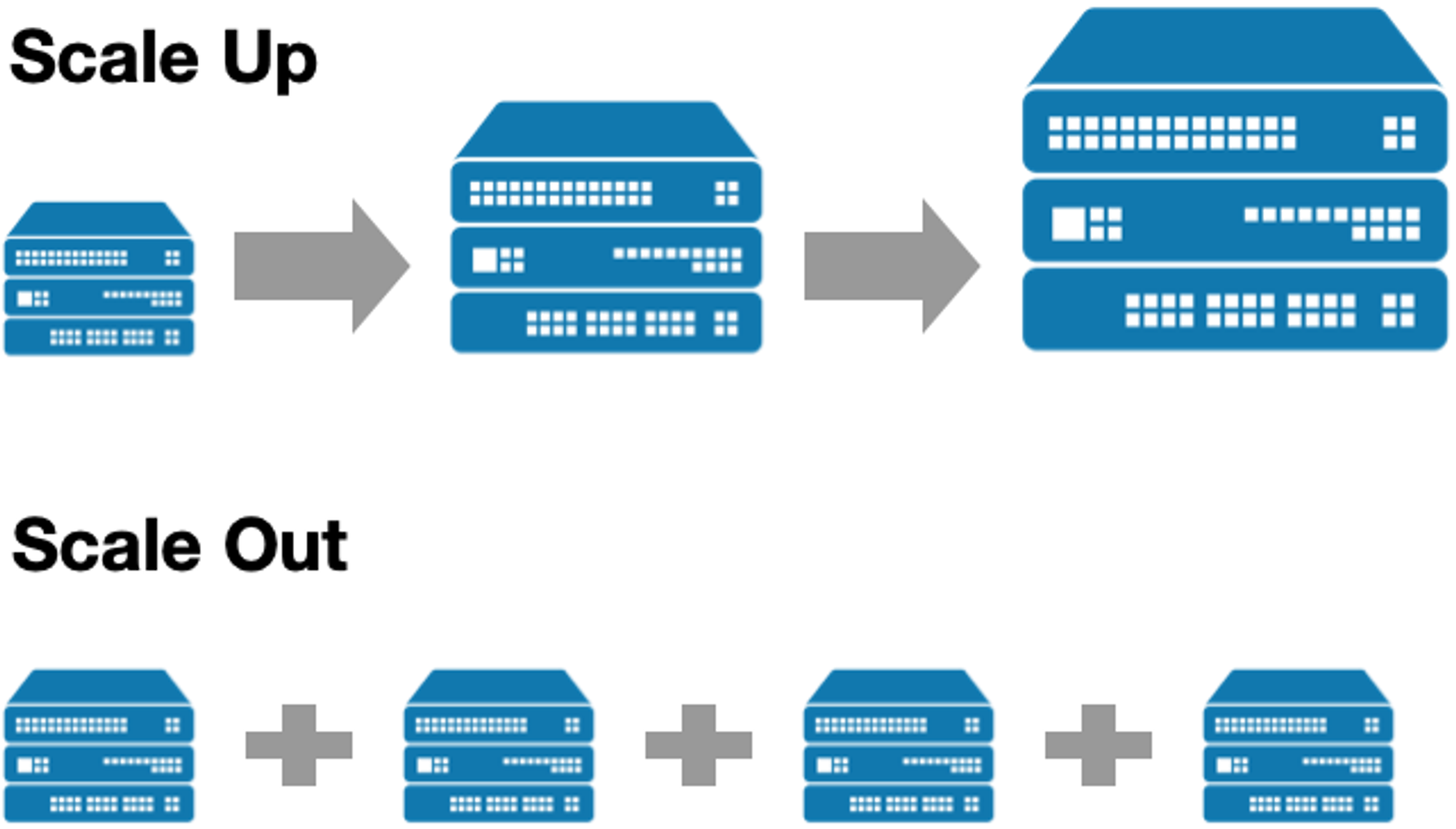
- 서버를 이용하다보면 사용자 증가 등으로 더많은 용량과 성능이 필요하게 된다.
- 이때 CPU, 메모리, 디스크 용량 등의 서버 스펙 자체를 올리는 것을
스케일업이라고 한다. - 반면 여러 대의 서버를 추가하여 확장하는 것을
스케일 아웃이라고 한다. - 이 스케일 아웃을 통해 적당한 성능의 서버 여러 대를 한 대처럼 이용하여 좋은 퍼포먼스를 얻을 수 있다.
누군가가 물어본다면
Redis는 인메모리 데이터 구조로 빠른 성능을 제공하며, 퍼시스턴스, 복제, 클러스터 등의 다양한 기능들을 지원합니다.
This post is licensed under CC BY 4.0 by the author.