MongoDB의 단일 도큐먼트 원자성
들어가며
스프링으로 MongoDB를 트랜잭션 없이 사용하면서 findAndModify로 동시성을 보장받을 수 있는 로직을 짜게 되었다.
어떻게 동시성을 보장할 수 있게 설계된 건지 궁금해서 찾아보게 되었다.
MongoDB는 WiredTiger 엔진의 도큐먼트 수준 잠금을 이용해 트랜잭션 없이도 단일 도큐먼트에 대한 원자성을 보장한다.
도큐먼트 수준 잠금은 무엇인지, 어떤 원리로 제공하는지 알아보자
Document-Level Locking
트랜잭션을 구성하기 위해선 레플리카 셋 설정이 필요하다.
하지만 트랜잭션 없이도 단일 도큐먼트에 대한 쓰기 작업은 원자성이 보장된다.
이러한 단일 도큐먼트 락은 다음과 같이 정의할 수 있다.
하나의 도큐먼트를 수정하는 동안, 해당 도큐먼트에만
Excluse Lock(배타적 락)을 걸어 다른 쓰기 작업이 동시에 해당 도큐먼트를 수정하지 못하도록 막는다
update, findAndModify, replace, delete 등의 쓰기 연산에 적용된다.
여러 도큐먼트나, 여러 컬렉션에 대한 작업에는 적용되지 않는 점을 주의해야 한다.
WiredTiger 데이터 저장 구조
공식 문서와 카카오 기술 블로그에 따르면 B+ Tree 기반 인메모리 페이지 시스템을 사용하며, 실제 도큐먼트의 위치 정보는 B+ Tree 리프 노드의 레코드 슬롯에 위치한다.
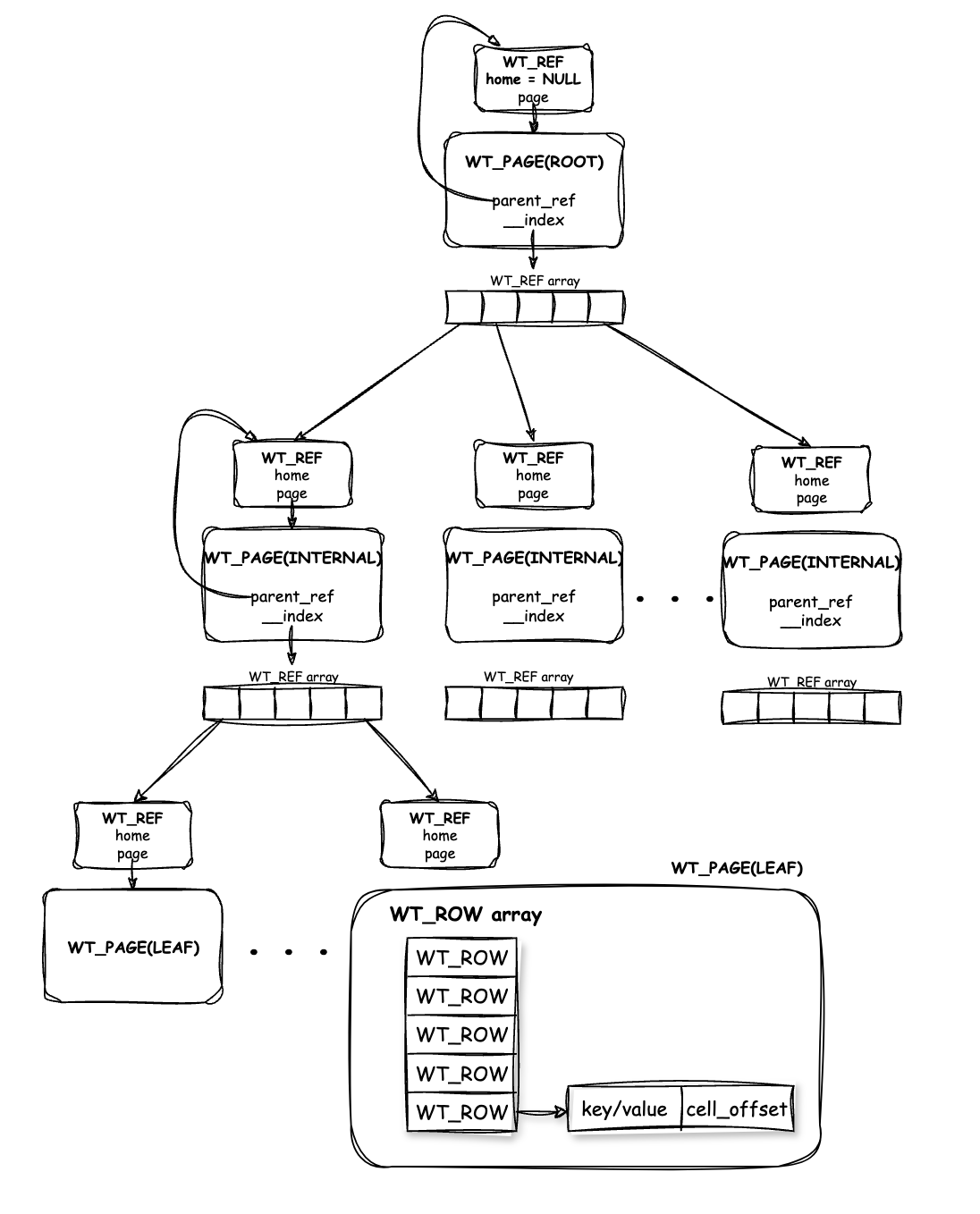
위 그림에서 리프 노드에 해당하는 페이지(WT_PAGE)는 여러 개의 WT_ROW 배열로 구성되어 있다.
각 WT_ROW는 하나의 도큐먼트를 식별하며, 해당 도큐먼트의 위치를 저장한다.
실제 BSON 데이터는
cell_offset이 가리키는 곳(WT_CELL)에 저장되어 있다.
쓰기 작업 프로세스
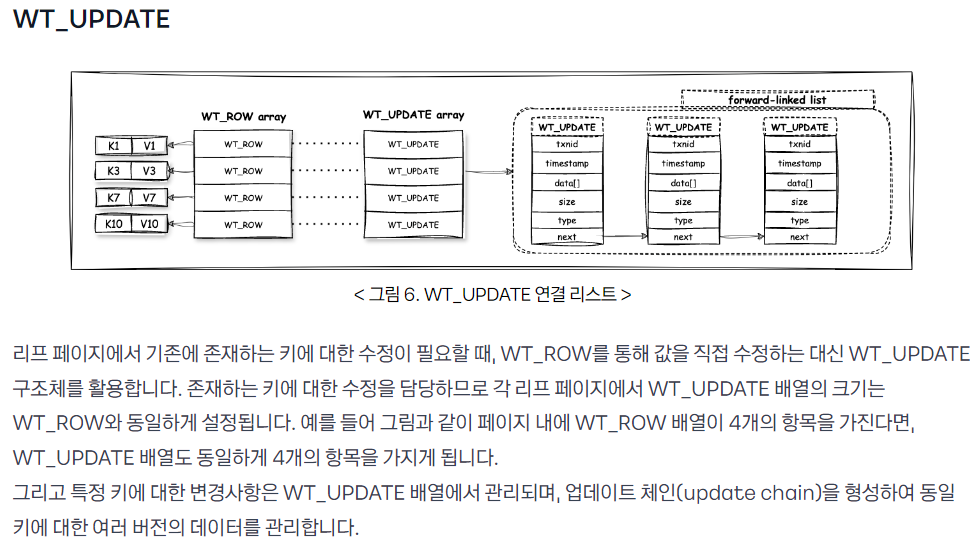
카카오 블로그 중 일부
update_chain에는 새로운 쓰기 작업의 결과가 차례대로 저장되고, 일정 주기 후 디스크에 반영된다.
- 쓰기 작업 요청 자체가 아닌 요청 결과가 WT_UPDATE로 저장된다.
이때 체인에 안전하게 추가하기 위해 latch lock이 걸린다.
카카오 블로그의 글처럼 WT_ROW 각각에 대응되는 WT_UPDATE 배열이 존재하고, WT_ROW는 하나의 도큐먼트에 대응되므로 결국 WT_UPDATE 체인에 대한 락은 단일 도큐먼트에 대한 락에 대응되는 것이다.
WiredTiger 엔진의 락 메커니즘과 데이터 구조 덕분에, MongoDB에서 단일 도큐먼트에 대한 쓰기 연산에서 동시성과 원자성을 보장받는다.
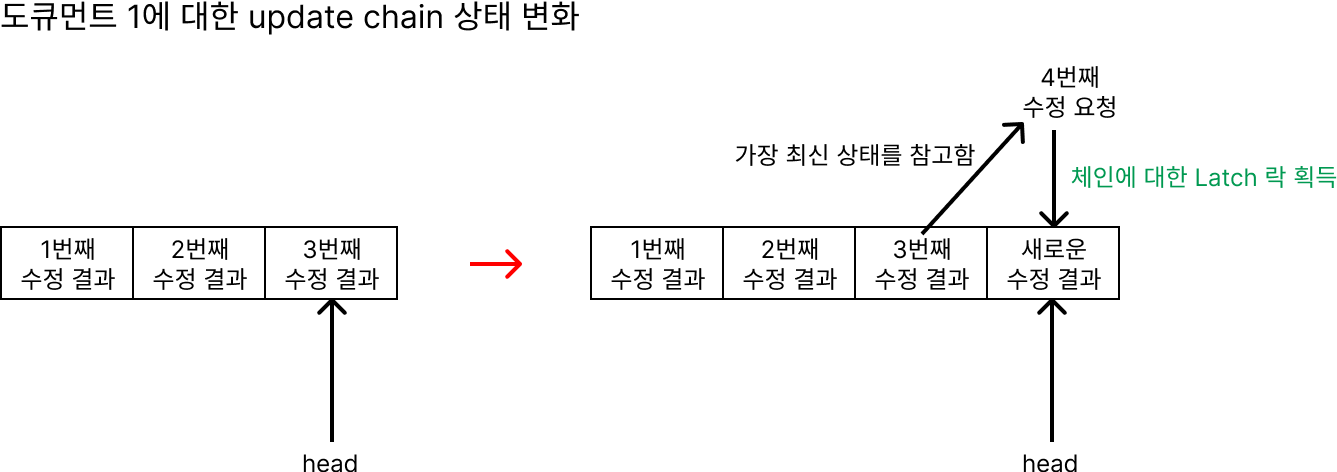
주의 - 멱등성을 가진 요청
https://www.mongodb.com/docs/manual/core/write-operations-atomicity/
MongoDB에서 단일 도큐먼트에 대한 쓰기 연산은 원자적이지만, 멱등성을 가지는 $set 연산을 잘못 사용할 경우, 동시성 문제가 발생할 수 있다고 설명한다.
예시
1
db.games.insertOne( { _id: 1, score: 80 } )
games 라는 컬렉션에 id는 1이고, score는 80인 도큐먼트가 있다.
이때 set을 사용하면 어떤 문제가 발생하는지 살펴보자
set - 수정 대상 필터가 변하는 경우
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// Update A
db.games.updateOne(
{ score: 80 },
{
$set: { score: 90 }
}
)
// Update B
db.games.updateOne(
{ score: 80 },
{
$set: { score: 100 }
}
)
두 요청이 동시에 수행되면, 하나가 먼저 실행되어 score 값을 변경한다.
이후 요청은 score:80 조건을 만족하지 않으므로 무시된다.
결과적으로 하나의 요청만 반영된다.
set - 수정 대상 필터가 변하지 않는 경우
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// Update A
db.games.updateOne(
{ _id: 1 },
{
$set: { score: 90 }
}
)
// Update B
db.games.updateOne(
{ _id: 1 },
{
$set: { score: 100 }
}
)
이 경우엔 어떨까?
id값은 변하지 않으므로 둘 다 정상적으로 수행된다.
그러나 A와 B는 각각 score: 80을 읽고, score: 90, score: 100으로 계산된 결과를 덮어쓴다.
앞서 수행된 요청의 결과를 무시하고 덮어쓰므로 그 요청은 논리적으로 무시된다.
이는 애플리케이션 동작에 예기치 않은 오류를 발생시킬 수 있다.
inc 연산자
set을 사용하는 두 가지 경우 모두, 최종 값이 110이 되어야 하는 상황이라면 큰 문제를 야기한다.
이는 update chain에서 최신 버전에 대해 수정한 결과를 기록하는 구조에서 비롯된다.
따라서 애플리케이션에서 계산하지 않고, 수정할 양 만큼의 값을 증가시키는 inc 연산자를 사용해야 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// Update A
db.games.updateOne(
{ _id: 1 },
{
$inc: { score: 10 }
}
)
// Update B
db.games.updateOne(
{ _id: 1 },
{
$inc: { score: 20 }
}
)
두 요청이 어떤 순서로 실행되든 최종 값은 항상 110이 된다.
경쟁 조건 없이 동시성 안전하게 처리되는 것이다.