GDG I/O Extended 2024 송도 컨퍼런스 후기
Posted
By ROOT
20 min read
서론
- 컨퍼런스를 좀 다니면서 개발자로써의 인사이트를 얻어야겠다고 생각하여 GDG에 참여하게 되었다.
- GDG가 무엇인지, 들은 세션에 대해 짧은 정리와 느낀점을 적어보겠다.
어떤 행사인가
- GDG I/O Extended 는
Google Developer Groups에서 주최하였다. - Google I/O의 주요 발표 내용을 공유하고, 지역 개발자 커뮤니티와 함께 최신 기술과 트렌드를 논의하는 자리이다.
- 구글의 기술 이야기를 들어볼 수 있을까 기대했지만, 그런 세션은 거의 없었고 대부분 다양한 회사에서의 개발 이야기가 주를 이루었다.
- 실제로 백엔드 세션을 위주로 들었는데 구글 관련 이야기는 하나도 못들었다.
편성표

1. 에어프레미아는 왜 재개발을 하는가?
- 에어프레미아는 LCC(저가항공)을 기반으로 장거리 노선까지 합리적인 비용으로 제공하고자 하는 항공사다.
- 기존 LCC에서 장거리 노선까지 제공하는 하이브리드 형태 HSC로 전략을 변경하면서 기존의 레거시 코드에 혁신이 필요했다.
[기존 레거시 코드의 문제점]
JSP기반이다.- JSP는 HTML 코드 페이지에 자바 코드를 같이 작성하는 형태의 기술이다.
- 이 때문에 프론트, 백엔드가 하나의 레포지토리에서 작업을 했고, 이는 유지보수가 어려운 형태가 되었다.
- 하나의 파일에서 너무 많은 책임을 지니기 때문에 작은 변경이 어떤 파급 효과를 불러올지 모르는 위험한 코드인 것이다.
navitaire라는 외부 API를 사용하기 위한 커넥션 관리가 제대로 안되었다.RestTemplate,커넥션을 생성하는 팩토리를 사용하면서 빈으로 등록하는 방법이 아닌 함수 안에서new로 생성하는 형태였다.- 이는 매 요청마다 새로운 커넥션을 1개도 아닌 여러개를 생성하게 된다.
- 따라서 낭비되는 커넥션이 늘어나고 성능 저하가 발생되는 것이다.
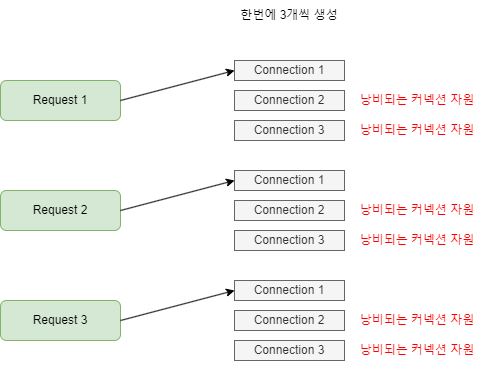
[어떻게 해결했는가]
- FE/BE 분리
- JSP 기술을 버리고 FE 서버, BE 서버를 분리하였다.
- 이를 통해 책임이 분배되고 더 쉬운 유지보수가 가능해진다.
- 사실 최근에 개발을 배우는 사람들이라면 이 구조가 당연하다고 느껴질 것이다.
navitaireClient설계- 커넥션 관리가 제대로 안되는 문제와 더불어, API 사용을 위한 쿼리가 문자열로 짜여 오류를 발견하기 힘든 구조를 해결하였다.
- 커넥션 풀이 도입되었다.
- REST API,
graphQLAPI 등을 처리하는 컴포넌트를 두어 외부 API를 좀 더 편리하게 쓸 수 있도록 개선되었다.
- 코틀린 사용
- 자바 언어의 불편함을 느끼고 코틀린을 채택하였다.
- 코틀린으로 넘어간 사람들의 대다수는 다시는 자바로 돌아가고 싶지 않다고 말할 정도로 생산성이 높다.
[느낀점]
- 기대는 별로 안했지만 생각보다 꽤 유익했던 것 같다.
- 흔히 개발자들이 기피하는 중소기업 이미지를 갓 벗어난 회사라고 느껴졌다.
- 지금까지 이론으로만 배워왔던 내용들로 레거시 코드가 개선된 사례를 들어보니 나의 지식이 좀 더 탄탄해진 느낌이었다.
2. 최대 동접 10만 트래픽을 소화하는 올리브영 온라인몰의 전시 전략
- 부제 - 올리브영 전시 영역의 꺾이지 않는 안정성
- 여기서 말하는
전시는 사람들에게 보여지는 상품 이미지, 상품 정보들을 말한다.
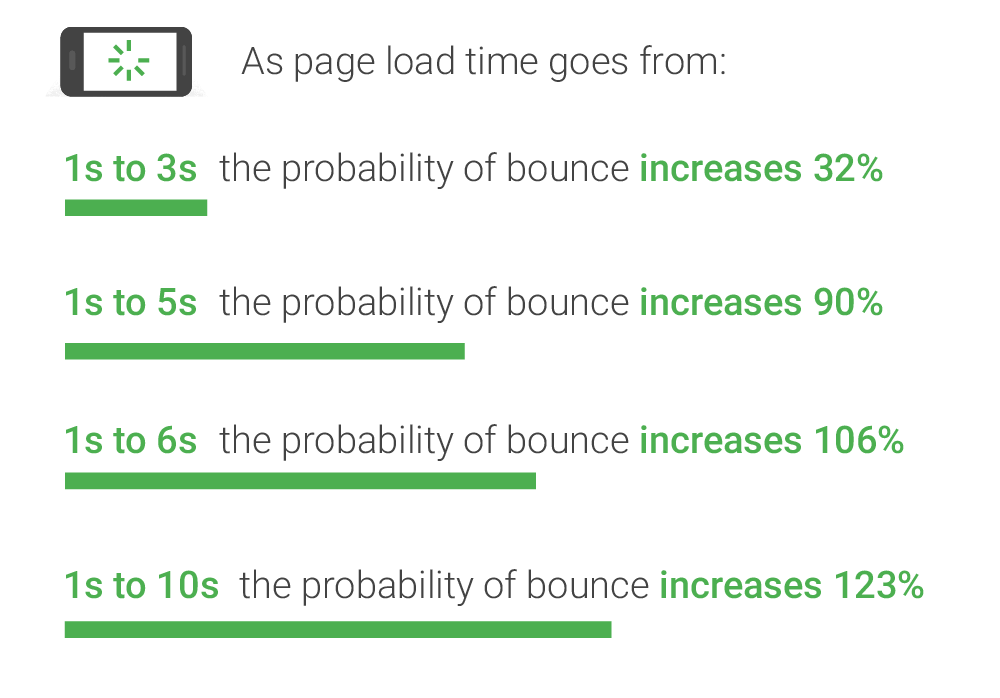
- 페이지 로딩 시간이 길어질수록 사용자 이탈 확률은 급격하게 증가한다.
- 올리브영은 로딩 시간으로 인한 사용자 이탈, 불만들을 해결하기 위해 어떠한 방법들을 사용했는지 소개했다.
[초기 레거시 아키텍처]
- 모놀리식 아키텍처
- 이 아키텍처는 단일 코드베이스/단일 배포 단위로 구성되는 가장 기본적인 아키텍처다.
- 단순하지만 규모가 커질수록 복잡해지고, 도메인 간의 결합도가 높아져 유지보수가 어려워진다.
- 온프레미스(On-Premises)
- 소프트웨어와 하드웨어를 조직의 자체 데이터 센터에 설치하고 운영하는 방식을 말한다.
AWS,GCP같은 클라우드 서비스와 대조된다.
- 올리브영은 온프레미스로 관리하면서 다음과 같은 문제점을 겪었다.
- 자원을 최대로 사용해도 서버가 죽는 문제
Scale Up,Scale Out의 어려움과 복잡성
- 엔터프레이즈 레거시
- 외주 형태로 개발되어 히스토리를 아는 개발자가 없어 난항을 겪었다고 한다.
[어떻게 해결했는가]
- MSA(Micro Service Architecture)를 도입하여 전시 전용 백엔드 서버를 구축하였다.
- 회원 관리, 주문과 같은 도메인들을 분리하여 전시 관련 컨텐츠만 제공하는 서버를 구축하였다.
- 덕분에 하나의 도메인이 죽어도 다른 도메인은 살아있는 효과를 볼 수 있었다.
- 또한 전시 도메인에만 집중하므로 성능도 더 좋아졌다.
- 캐시 시스템 구축
- 성능 저하의 원인을 살펴보니 대부분이 RDB 접근 영역에서 발생하였다고 한다.
- 이를 해결하기 위해
Redis를 사용하여 캐시 시스템을 구축했다.캐시 어사이드 전략 채택,
TTL(Time To Live)등을 사용하였다. 정리 글 참고 - cache stampede
- 캐시 어사이드로 사용하면 캐시 서버에 데이터가 없을 시(
miss) RDB에 접근하여 데이터를 가져온다. - TTL은 유효기간이 지나면 자동으로 데이터가 삭제되는 기능이다.
캐시 스탬피드는 TTL로 키 값이 사라지는 경우 캐시 미스로 처리되어 RDB 접근이 순간적으로 많아지는 현상을 뜻한다.- 이를 해결하기 위해
noSQL을 두어 전시 데이터를 사전 가공 및 보관하였다.
- Mongo DB 사용
- 다양한 형태의 전시 데이터를 기존 RDB에서 관리하기에는 유연성이 떨어졌다고 한다.
- 이에 스키마가 없고 안정성과 유연성이 뛰어난 Mongo DB를 도입했다.
- 전시 데이터 오류 최소화를 위한 버전 관리
- 배치로 시간마다 검증작업을 수행하여 유효하지 않은 데이터가 들어오면 슬랙 웹훅을 통해
invalid collection으로 저장하여 확인한다. - 정상이라면 레디스에 저장하여 서빙한다.
- 배치로 시간마다 검증작업을 수행하여 유효하지 않은 데이터가 들어오면 슬랙 웹훅을 통해
- 캐싱 데이터 세분화
- 한번에 모든 데이터를 받아오는 것이 아닌 나눠서 받아온다.
- 페이지네이션처럼, 스크롤을 내릴 때마다 추가 전시 데이터를 받아온다고 보면 된다.
- 고가용성 달성
- 전시 데이터는 레디스 서버에서 제공하고 있다.
- 그럼 레디스 서버가 죽는다면?
mongoDB로 서빙한다.- 또 죽으면?
oracleDB로 서빙한다.- 이렇게 예비 발전기처럼 비상 시를 대비하는 DB를 두어 서비스가 완전히 마비되지 않도록 방지한다.
- 이를
서킷 브레이커 3중 방어 코드라고 한다.
- 이 외에 On/Off 플래그 같은 기술을 사용하였다.
[느낀점]
- 내가 모르는 엄청난 기술들을 기대했지만, 생각보다 이론적으로 알고 있던 내용들을 얕게 소개한 느낌이어서 약간은 실망했다.
- 그래도 캐시 스탬피드, 레디스 사용에 대한 얘기는 흥미로웠다.
- 또 레거시 코드에 대한 인식 얘기도 해주셨는데 감명을 받았다.
레거시 코드는 오래 살아남았다는 증거이므로 안좋게만 바라볼 필요는 없고, 어떻게 하면 고칠 수 있을지 생각해보는 게 더 좋다.
3. 사수 없는 주니어 개발자가 성장하는 방법
- 사수 없는 개발자는 거르라고 많이 조언을 한다.
- 강연자 분은 사수가 없어도 성장할 수 있다면서 방법을 제시한다.
- 발표
- 블로그
- 커뮤니티
- 스터디 / 사이드 프로젝트
- 연합 동아리
- 오픈소스
- 야근(?)
- 현장실습에서 일을 하면서 야근을 하지만 내가 하는 야근과는 조금 다른 결의 야근을 말한 것 같다.
- 그저 끝나지 않는 회사일을 더 하는 야근이 아니라, 시간에 쫓겨 날림 공사를 한 코드를 보완하기 위해 야근을 하는 것이다.
- 하지만 현실은 끝나지 않는 일을 처리하기 바쁘다.
- 일의 양에 압도당하지 않고 코드를 개선할 수 있는 시간이 있는 회사라면 그것이 대기업 못지 않은 좋은 회사라고 생각한다.
[느낀점]
- 사실 6번 빼고는 다 하는 것들이라 비법 같은것을 기대했지만 역시 없었다.
- 결국은 즐겨야 한다. 이 사실을 알기 때문에 최대한 즐길려고 노력하고 있다.
- Q&A에서 가장 인상적이었던 것은 시장에 뒤떨어진다는 생각을 하지 않는다는 것이었다. 항상 조바심을 느끼는 나에게 필요한 태도이다.
기술주의자 v 논리주의자
- Microsoft MVP로 뽑히신 분의 강의였다.
- MVP답게 천재성이 돋보이는 분이었다.
구현체가 아닌 인터페이스에 집중해라.무슨 말인지는 대충 알겠으나, 개발을 최소 5년은 한 뒤에야 이해할 수 있는 강연이었던 것 같았다.- 아직은 이르기에
중간에 도망쳤다 ㅎㅎ
DB를 느리게 만드는 다양한 방법들
부제 - 왜 내가 만든 쿼리는 항상 느릴까?
- 인덱스에 대해 설명하고, DB의 성능을 끌어올리기 위해 어떻게 튜닝하는지, 인덱스 전략을 어떻게 효율적이게 짤 수 있는지를 알 수 있었다.
- 백엔드보다는 DBA 직무에 더 도움이 될만한 강연이었다.
- 대학교 수업 같았다.(
절대 잠깐 졸았던 것 아님) - 그럼에도 수많은 테이블을 조인하면서 쿼리를 짜는 나에게 어떻게 쿼리를 짜고, 읽을지 등의 조언을 얻을 수 있어 좋았다.
스프링 AI 입문하기 with Gemini
- 토비 님의 강의를 통해 살짝 들었던 스프링 AI에 관한 이야기다.
사실 제일 궁금했고 기대됐던 세션이었다.
- 지금까지 AI 사용에 있어 자바는 할 수 있는 역할이 없었다.
하지만 생성형 AI가 발전하면서 HTTP를 통해서 사전 훈련된 모델과의 상호작용이 가능해짐으로써 스프링 AI 가 대두되었다.
강연자 분은 스프링 AI를 이용한 애플리케이션으로, 포켓몬 GO 도우미 제작 일지를 소개하였다.

- 애플리케이션 제작 과정은 다음과 같다.
- 스프링 AI가 사용하는 기본 LLM 모델이 가지고 있는 데이터를 확인한다.
- 타입 상성을 물어봤을 때 약점인 포켓몬들에 대한 설명이 존재하지 않는 포켓몬으로, 할루시네이션의 발생을 확인하였다.
- 이를 통해 기존 LLM 모델에 추가적인 데이터 주입(
검색 증강 생성)이 필요함을 확인하였다.
- 필요한 정보 수집/가공
- 포켓몬 정보 제공 API로부터 정보를 수집한다.
- 필요한 데이터 형식에 맞게 가공, 즉 전처리한다.
수많은 데이터를 직접 한땀한땀 가공하셨다고 한다..
- ETL Pipeline
- 가공한 데이터를 추출, 변환, 로드하는 과정이다.
- 스프링 AI에서 제공되는 메서드를 통해 쉽게 처리할 수 있다.
- 벡터 데이터베이스 연동하기
- 유사도 정보 제공을 위해 벡터 데이터베이스를 연동하였다.
- 이 과정에서 많은 이슈들이 발생하였다.
벡터 데이터베이스 존재하지 않음, 버전 맞추기, 차원 수 맞추기 등
- 스프링 AI가 사용하는 기본 LLM 모델이 가지고 있는 데이터를 확인한다.
[느낀점]
- 생각보다 싱거웠지만 심심풀이 땅콩 느낌으로 나쁘지 않았다.
- Spring AI는 최근에 나온만큼 이슈도 많고 기술도 빠르게 변한다.
- 아직은 제대로 사용되기엔 1~2년은 걸릴 것 같다.
- 또 자바가 파이썬을 대체하기에는 이미 잘 구축되어있는 라이브러리들로 인해
굳이?라는 생각이 들 것 같다.
총평
- 어린 친구들도 많은 만큼 뭔가 깊은 주제를 다루지는 않았다.
- 나는 처음 듣는 기술이나 신기한 기술들을 들을 것이라 기대했기에 좀 실망스럽긴 했다.
- 하지만 한번쯤은 가볼만 하다!
This post is licensed under CC BY 4.0 by the author.